使用 Spring Statemachine
参考文档的这一部分解释了 Spring Statemachine 为任何基于 Spring 的应用程序提供的核心功能。
它包括以下主题:
-
状态机配置 描述了通用的配置支持。
-
状态机 ID 描述了机器 ID 的使用。
-
状态机工厂 描述了通用的状态机工厂支持。
-
使用延迟事件 描述了延迟事件的支持。
-
使用作用域 描述了作用域的支持。
-
使用动作 描述了动作的支持。
-
使用守卫 描述了守卫的支持。
-
使用扩展状态 描述了扩展状态的支持。
-
使用 StateContext 描述了状态上下文的支持。
-
触发转换 描述了触发的使用。
-
监听状态机事件 描述了状态机监听器的使用。
-
上下文集成 描述了通用的 Spring 应用上下文支持。
-
使用 StateMachineAccessor 描述了状态机内部访问器的支持。
-
使用 StateMachineInterceptor 描述了状态机错误处理的支持。
-
状态机安全性 描述了状态机安全性的支持。
-
状态机错误处理 描述了状态机拦截器的支持。
-
状态机服务 描述了状态机服务的支持。
-
持久化状态机 描述了状态机持久化的支持。
-
Spring Boot 支持 描述了 Spring Boot 的支持。
-
监控状态机 描述了监控和跟踪的支持。
-
使用分布式状态 描述了分布式状态机的支持。
-
测试支持 描述了状态机测试的支持。
-
Eclipse 建模支持 描述了状态机 UML 建模的支持。
-
仓库支持 描述了状态机仓库配置的支持。
状态机配置
在使用状态机时,常见的任务之一是设计其运行时配置。本章重点介绍如何配置 Spring Statemachine,以及它如何利用 Spring 的轻量级 IoC 容器来简化应用程序的内部结构,使其更易于管理。
本节中的配置示例并不是功能完整的。也就是说,你始终需要同时定义状态和转换。否则,状态机的配置将是不完整的。我们只是通过省略其他需要的部分,使代码片段更加简洁。
使用 enable 注解
我们使用了两个熟悉的 Spring enabler 注解来简化配置:@EnableStateMachine 和 @EnableStateMachineFactory。这些注解放在 @Configuration 类中时,会启用状态机所需的一些基本功能。
当你需要一个配置来创建 StateMachine 实例时,可以使用 @EnableStateMachine。通常,一个 @Configuration 类会扩展适配器(EnumStateMachineConfigurerAdapter 或 StateMachineConfigurerAdapter),这允许你重写配置回调方法。我们会自动检测你是否使用了这些适配器类,并相应地修改运行时配置逻辑。
当你需要一个配置来创建 StateMachineFactory 的实例时,你可以使用 @EnableStateMachineFactory。
这些的使用示例将在以下部分中展示。
配置状态
在本指南稍后的部分中,我们将深入探讨更复杂的配置示例,但首先我们从简单的开始。对于大多数简单的状态机,你可以使用 EnumStateMachineConfigurerAdapter 来定义可能的状态,并选择初始状态和可选的结束状态。
@Configuration
@EnableStateMachine
public class Config1Enums
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
}
你也可以使用字符串代替枚举作为状态和事件,通过使用 StateMachineConfigurerAdapter,如下一个示例所示。大多数配置示例使用枚举,但一般来说,你可以互换使用字符串和枚举。
@Configuration
@EnableStateMachine
public class Config1Strings
extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("S1")
.end("SF")
.states(new HashSet<String>(Arrays.asList("S1","S2","S3","S4")));
}
}
使用枚举可以带来更安全的状态和事件类型,但将可能的组合限制在编译时。字符串没有这种限制,允许你使用更动态的方式来构建状态机配置,但不提供相同级别的安全性。
配置层次状态
你可以通过使用多个 withStates() 调用来定义层次化状态,其中你可以使用 parent() 来指示这些特定状态是某个其他状态的子状态。以下示例展示了如何做到这一点:
@Configuration
@EnableStateMachine
public class Config2
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.state(States.S1)
.and()
.withStates()
.parent(States.S1)
.initial(States.S2)
.state(States.S2);
}
}
配置区域
没有特殊的配置方法来标记一组状态为正交状态的一部分。简单来说,当同一个层次状态机拥有多组状态,且每组状态都有一个初始状态时,正交状态就被创建了。因为一个独立的状态机只能有一个初始状态,多个初始状态意味着某个特定状态必须拥有多个独立的区域。以下示例展示了如何定义这些区域:
@Configuration
@EnableStateMachine
public class Config10
extends EnumStateMachineConfigurerAdapter<States2, Events> {
@Override
public void configure(StateMachineStateConfigurer<States2, Events> states)
throws Exception {
states
.withStates()
.initial(States2.S1)
.state(States2.S2)
.and()
.withStates()
.parent(States2.S2)
.initial(States2.S2I)
.state(States2.S21)
.end(States2.S2F)
.and()
.withStates()
.parent(States2.S2)
.initial(States2.S3I)
.state(States2.S31)
.end(States2.S3F);
}
}
在持久化带有区域的机器或通常依赖任何功能来重置机器时,您可能需要为区域设置一个专用的 ID。默认情况下,此 ID 是一个生成的 UUID。如下例所示,StateConfigurer 有一个名为 region(String id) 的方法,允许您为区域设置 ID:
@Configuration
@EnableStateMachine
public class Config10RegionId
extends EnumStateMachineConfigurerAdapter<States2, Events> {
@Override
public void configure(StateMachineStateConfigurer<States2, Events> states)
throws Exception {
states
.withStates()
.initial(States2.S1)
.state(States2.S2)
.and()
.withStates()
.parent(States2.S2)
.region("R1")
.initial(States2.S2I)
.state(States2.S21)
.end(States2.S2F)
.and()
.withStates()
.parent(States2.S2)
.region("R2")
.initial(States2.S3I)
.state(States2.S31)
.end(States2.S3F);
}
}
配置过渡效果
我们支持三种不同类型的转换:external、internal 和 local。转换可以由信号(即发送到状态机的事件)或定时器触发。以下示例展示了如何定义这三种类型的转换:
@Configuration
@EnableStateMachine
public class Config3
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.S1).target(States.S2)
.event(Events.E1)
.and()
.withInternal()
.source(States.S2)
.event(Events.E2)
.and()
.withLocal()
.source(States.S2).target(States.S3)
.event(Events.E3);
}
}
配置 Guards
你可以使用守卫(guards)来保护状态转换。你可以使用 Guard 接口来进行评估,该方法可以访问 StateContext。以下示例展示了如何做到这一点:
@Configuration
@EnableStateMachine
public class Config4
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.S1).target(States.S2)
.event(Events.E1)
.guard(guard())
.and()
.withExternal()
.source(States.S2).target(States.S3)
.event(Events.E2)
.guardExpression("true");
}
@Bean
public Guard<States, Events> guard() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return true;
}
};
}
}
在前面的示例中,我们使用了两种不同类型的 guard 配置。首先,我们创建了一个简单的 Guard 作为 bean,并将其附加到状态 S1 和 S2 之间的转换上。
其次,我们使用了一个 SPeL 表达式作为守卫,规定该表达式必须返回一个 BOOLEAN 值。在幕后,这个基于表达式的守卫是一个 SpelExpressionGuard。我们将其附加到状态 S2 和 S3 之间的转换上。这两个守卫始终评估为 true。
配置 Actions
你可以定义与过渡和状态一起执行的操作。操作总是作为源自触发器的过渡的结果运行。以下示例展示了如何定义一个操作:
@Configuration
@EnableStateMachine
public class Config51
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.S1)
.target(States.S2)
.event(Events.E1)
.action(action());
}
@Bean
public Action<States, Events> action() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
// do something
}
};
}
}
在前面的示例中,一个 Action 被定义为一个名为 action 的 bean,并与从 S1 到 S2 的转换相关联。以下示例展示了如何多次使用一个动作:
@Configuration
@EnableStateMachine
public class Config52
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1, action())
.state(States.S1, action(), null)
.state(States.S2, null, action())
.state(States.S2, action())
.state(States.S3, action(), action());
}
@Bean
public Action<States, Events> action() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
// do something
}
};
}
}
通常,你不会为不同的阶段定义相同的 Action 实例,但我们在这里这样做是为了避免在代码片段中引入过多的噪音。
在前面的示例中,一个名为 action 的 bean 定义了一个 Action,并与状态 S1、S2 和 S3 相关联。我们需要明确这里发生了什么:
-
我们为初始状态
S1定义了一个动作。 -
我们为状态
S1定义了一个进入动作,并将退出动作留空。 -
我们为状态
S2定义了一个退出动作,并将进入动作留空。 -
我们为状态
S2定义了一个单一的状态动作。 -
我们为状态
S3定义了进入和退出动作。 -
注意,状态
S1使用了initial()和state()函数两次。只有在你想为初始状态定义进入或退出动作时才需要这样做。
使用 initial() 函数定义的动作仅在状态机或子状态启动时运行特定的动作。此动作是一个初始化动作,仅运行一次。如果状态机在初始状态和非初始状态之间来回转换,则使用 state() 定义的动作将被运行。
状态操作
状态动作的执行方式与入口和出口动作不同,因为状态动作的执行发生在状态进入之后,并且如果在特定动作完成之前发生状态退出,则可以取消该动作的执行。
状态操作通过使用 Reactor 的默认并行调度器进行订阅,以正常的响应式流程执行。这意味着,无论你在操作中做什么,你都需要能够捕获 InterruptedException,或者更一般地说,定期检查 Thread 是否被中断。
以下示例展示了使用默认 IMMEDIATE_CANCEL 的典型配置,当任务状态完成时,它将立即取消正在运行的任务:
@Configuration
@EnableStateMachine
static class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config) throws Exception {
config
.withConfiguration()
.stateDoActionPolicy(StateDoActionPolicy.IMMEDIATE_CANCEL);
}
@Override
public void configure(StateMachineStateConfigurer<String, String> states) throws Exception {
states
.withStates()
.initial("S1")
.state("S2", context -> {})
.state("S3");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions) throws Exception {
transitions
.withExternal()
.source("S1")
.target("S2")
.event("E1")
.and()
.withExternal()
.source("S2")
.target("S3")
.event("E2");
}
}
你可以为每台机器设置一个策略为 TIMEOUT_CANCEL 并配合一个全局超时时间。这将改变状态行为,使其在请求取消之前等待操作完成。以下示例展示了如何实现这一点:
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config) throws Exception {
config
.withConfiguration()
.stateDoActionPolicy(StateDoActionPolicy.TIMEOUT_CANCEL)
.stateDoActionPolicyTimeout(10, TimeUnit.SECONDS);
}
如果 Event 直接将机器带入一个状态,使得事件头对特定操作可用,你也可以使用专用的事件头来设置特定的超时(以 millis 定义)。为此,你可以使用保留的头值 StateMachineMessageHeaders.HEADER_DO_ACTION_TIMEOUT。以下示例展示了如何做到这一点:
@Autowired
StateMachine<String, String> stateMachine;
void sendEventUsingTimeout() {
stateMachine
.sendEvent(Mono.just(MessageBuilder
.withPayload("E1")
.setHeader(StateMachineMessageHeaders.HEADER_DO_ACTION_TIMEOUT, 5000)
.build()))
.subscribe();
}
过渡动作错误处理
你始终可以手动捕获异常。然而,通过为转换定义操作,你可以定义一个错误操作,当异常被抛出时,该操作将被调用。然后,异常可以从传递给该操作的 StateContext 中获取。以下示例展示了如何创建一个处理异常的状态:
@Configuration
@EnableStateMachine
public class Config53
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.S1)
.target(States.S2)
.event(Events.E1)
.action(action(), errorAction());
}
@Bean
public Action<States, Events> action() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
throw new RuntimeException("MyError");
}
};
}
@Bean
public Action<States, Events> errorAction() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
// RuntimeException("MyError") added to context
Exception exception = context.getException();
exception.getMessage();
}
};
}
}
如果需要,你可以手动为每个操作创建类似的逻辑。以下示例展示了如何做到这一点:
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.S1)
.target(States.S2)
.event(Events.E1)
.action(Actions.errorCallingAction(action(), errorAction()));
}
状态动作错误处理
处理状态转换中错误的逻辑也适用于进入状态和退出状态。
对于这些情况,StateConfigurer 提供了 stateEntry、stateDo 和 stateExit 方法。这些方法定义了 error 操作以及一个正常的(非错误的)action。以下示例展示了如何使用这三个方法:
@Configuration
@EnableStateMachine
public class Config55
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.stateEntry(States.S2, action(), errorAction())
.stateDo(States.S2, action(), errorAction())
.stateExit(States.S2, action(), errorAction())
.state(States.S3);
}
@Bean
public Action<States, Events> action() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
throw new RuntimeException("MyError");
}
};
}
@Bean
public Action<States, Events> errorAction() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
// RuntimeException("MyError") added to context
Exception exception = context.getException();
exception.getMessage();
}
};
}
}
配置伪状态
伪状态的配置通常通过配置状态和转换来完成。伪状态会自动作为状态添加到状态机中。
初始状态
你可以使用 initial() 方法将特定状态标记为初始状态。这个初始操作非常有用,例如,可以用来初始化扩展的状态变量。以下示例展示了如何使用 initial() 方法:
@Configuration
@EnableStateMachine
public class Config11
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1, initialAction())
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
@Bean
public Action<States, Events> initialAction() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
// do something initially
}
};
}
}
终止状态
你可以通过使用 end() 方法将某个特定状态标记为结束状态。每个子状态机或区域最多只能调用一次 end() 方法。以下示例展示了如何使用 end() 方法:
@Configuration
@EnableStateMachine
public class Config1Enums
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
}
状态历史
你可以为每个状态机定义一次状态历史。你需要选择其状态标识符,并设置 History.SHALLOW 或 History.DEEP。以下示例使用了 History.SHALLOW:
@Configuration
@EnableStateMachine
public class Config12
extends EnumStateMachineConfigurerAdapter<States3, Events> {
@Override
public void configure(StateMachineStateConfigurer<States3, Events> states)
throws Exception {
states
.withStates()
.initial(States3.S1)
.state(States3.S2)
.and()
.withStates()
.parent(States3.S2)
.initial(States3.S2I)
.state(States3.S21)
.state(States3.S22)
.history(States3.SH, History.SHALLOW);
}
@Override
public void configure(StateMachineTransitionConfigurer<States3, Events> transitions)
throws Exception {
transitions
.withHistory()
.source(States3.SH)
.target(States3.S22);
}
}
此外,如前面的示例所示,你可以选择性地定义一个从历史状态到同一状态机中某个状态顶点的默认转换。这种转换在特定情况下会作为默认行为发生,例如,如果状态机从未被进入过——因此,没有历史记录可用。如果没有定义默认的状态转换,则会按照正常方式进入区域。如果状态机的历史记录是一个最终状态,也会使用这个默认转换。
选择状态
为了使选择功能正常工作,需要在状态和转换中都定义选择。你可以通过使用 choice() 方法将特定状态标记为选择状态。在为此选择配置转换时,该状态需要与源状态匹配。
你可以通过使用 withChoice() 来配置一个转换,其中你需要定义源状态和一个 first/then/last 结构,这相当于一个普通的 if/elseif/else 结构。使用 first 和 then 时,你可以指定一个守卫(guard),就像你在 if/elseif 子句中使用条件一样。
一个 transition 必须能够存在,因此你必须确保使用 last。否则,配置将是无效的。以下示例展示了如何定义一个 choice state:
@Configuration
@EnableStateMachine
public class Config13
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.SI)
.choice(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withChoice()
.source(States.S1)
.first(States.S2, s2Guard())
.then(States.S3, s3Guard())
.last(States.S4);
}
@Bean
public Guard<States, Events> s2Guard() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return false;
}
};
}
@Bean
public Guard<States, Events> s3Guard() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return true;
}
};
}
}
动作可以在选择伪状态(choice pseudostate)的进入和退出转换中运行。如下例所示,定义了一个虚拟的 lambda 动作,该动作引导进入选择状态,并且为其中一个退出转换定义了一个类似的虚拟 lambda 动作(其中还定义了一个错误动作):
@Configuration
@EnableStateMachine
public class Config23
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.SI)
.choice(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.SI)
.action(c -> {
// action with SI-S1
})
.target(States.S1)
.and()
.withChoice()
.source(States.S1)
.first(States.S2, c -> {
return true;
})
.last(States.S3, c -> {
// action with S1-S3
}, c -> {
// error callback for action S1-S3
});
}
}
Junction 具有相同的 API 格式,意味着可以类似地定义操作。
连接状态
为了使系统正常工作,你需要在状态和转换中都定义一个连接点。你可以通过使用 junction() 方法将特定状态标记为选择状态。当为这个选择配置转换时,该状态需要与源状态匹配。
你可以通过使用 withJunction() 来配置过渡,其中你定义了源状态和一个 first/then/last 结构(这相当于一个普通的 if/elseif/else)。在 first 和 then 中,你可以指定一个守卫(guard),就像你在 if/elseif 子句中使用条件一样。
一个转换需要能够存在,因此你必须确保使用 last。否则,配置将是无效的。以下示例使用了 junction:
@Configuration
@EnableStateMachine
public class Config20
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.SI)
.junction(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withJunction()
.source(States.S1)
.first(States.S2, s2Guard())
.then(States.S3, s3Guard())
.last(States.S4);
}
@Bean
public Guard<States, Events> s2Guard() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return false;
}
};
}
@Bean
public Guard<States, Events> s3Guard() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return true;
}
};
}
}
choice 和 junction 的区别纯粹是理论上的,因为两者都是通过 first/then/last 结构实现的。然而,从理论上讲,基于 UML 建模,choice 只允许一个进入的转换,而 junction 允许多个进入的转换。在代码层面上,它们的功能几乎完全相同。
分叉状态
为了使其正常工作,你必须在状态和转换中都定义一个分支。你可以通过使用 fork() 方法将某个特定状态标记为选择状态。当为此分支配置转换时,此状态需要与源状态匹配。
目标状态需要是一个超级状态或区域中的直接状态。使用超级状态作为目标会将所有区域带入初始状态。针对单个状态可以更受控地进入区域。以下示例使用了 fork:
@Configuration
@EnableStateMachine
public class Config14
extends EnumStateMachineConfigurerAdapter<States2, Events> {
@Override
public void configure(StateMachineStateConfigurer<States2, Events> states)
throws Exception {
states
.withStates()
.initial(States2.S1)
.fork(States2.S2)
.state(States2.S3)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S2I)
.state(States2.S21)
.state(States2.S22)
.end(States2.S2F)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S3I)
.state(States2.S31)
.state(States2.S32)
.end(States2.S3F);
}
@Override
public void configure(StateMachineTransitionConfigurer<States2, Events> transitions)
throws Exception {
transitions
.withFork()
.source(States2.S2)
.target(States2.S22)
.target(States2.S32);
}
}
连接状态
你必须在状态和转换中都定义一个 join,以确保其正常工作。你可以通过使用 join() 方法将某个特定状态标记为选择状态。这种状态在转换配置中不需要匹配源状态或目标状态。
你可以选择一个目标状态,当所有源状态都已连接时,转换将进入该目标状态。如果你使用状态托管区域作为源,则区域的结束状态将用作连接点。否则,你可以从区域中选择任何状态。以下示例使用了连接:
@Configuration
@EnableStateMachine
public class Config15
extends EnumStateMachineConfigurerAdapter<States2, Events> {
@Override
public void configure(StateMachineStateConfigurer<States2, Events> states)
throws Exception {
states
.withStates()
.initial(States2.S1)
.state(States2.S3)
.join(States2.S4)
.state(States2.S5)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S2I)
.state(States2.S21)
.state(States2.S22)
.end(States2.S2F)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S3I)
.state(States2.S31)
.state(States2.S32)
.end(States2.S3F);
}
@Override
public void configure(StateMachineTransitionConfigurer<States2, Events> transitions)
throws Exception {
transitions
.withJoin()
.source(States2.S2F)
.source(States2.S3F)
.target(States2.S4)
.and()
.withExternal()
.source(States2.S4)
.target(States2.S5);
}
}
你也可以从合并状态(join state)发起多个转移(transitions)。在这种情况下,我们建议你使用守卫(guards)并定义这些守卫,以确保在任何给定时间只有一个守卫的评估结果为 TRUE。否则,转移行为将不可预测。下面的示例展示了这一点,其中守卫检查扩展状态是否包含变量:
@Configuration
@EnableStateMachine
public class Config22
extends EnumStateMachineConfigurerAdapter<States2, Events> {
@Override
public void configure(StateMachineStateConfigurer<States2, Events> states)
throws Exception {
states
.withStates()
.initial(States2.S1)
.state(States2.S3)
.join(States2.S4)
.state(States2.S5)
.end(States2.SF)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S2I)
.state(States2.S21)
.state(States2.S22)
.end(States2.S2F)
.and()
.withStates()
.parent(States2.S3)
.initial(States2.S3I)
.state(States2.S31)
.state(States2.S32)
.end(States2.S3F);
}
@Override
public void configure(StateMachineTransitionConfigurer<States2, Events> transitions)
throws Exception {
transitions
.withJoin()
.source(States2.S2F)
.source(States2.S3F)
.target(States2.S4)
.and()
.withExternal()
.source(States2.S4)
.target(States2.S5)
.guardExpression("!extendedState.variables.isEmpty()")
.and()
.withExternal()
.source(States2.S4)
.target(States2.SF)
.guardExpression("extendedState.variables.isEmpty()");
}
}
退出与入口点状态
你可以使用入口点和出口点来更精确地控制子状态的进入和退出。以下示例使用 withEntry 和 withExit 方法来定义入口点:
@Configuration
@EnableStateMachine
static class Config21 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("S1")
.state("S2")
.state("S3")
.and()
.withStates()
.parent("S2")
.initial("S21")
.entry("S2ENTRY")
.exit("S2EXIT")
.state("S22");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("S1").target("S2")
.event("E1")
.and()
.withExternal()
.source("S1").target("S2ENTRY")
.event("ENTRY")
.and()
.withExternal()
.source("S22").target("S2EXIT")
.event("EXIT")
.and()
.withEntry()
.source("S2ENTRY").target("S22")
.and()
.withExit()
.source("S2EXIT").target("S3");
}
}
如上所示,您需要将特定的状态标记为 exit 和 entry 状态。然后,您可以创建到这些状态的普通转换,并指定 withExit() 和 withEntry(),分别表示这些状态的退出和进入。
配置通用设置
你可以使用 ConfigurationConfigurer 来配置部分常见的状态机配置。通过它,你可以为状态机设置 BeanFactory 和自动启动标志。它还允许你注册 StateMachineListener 实例,配置转换冲突策略和区域执行策略。以下示例展示了如何使用 ConfigurationConfigurer:
@Configuration
@EnableStateMachine
public class Config17
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineConfigurationConfigurer<States, Events> config)
throws Exception {
config
.withConfiguration()
.autoStartup(true)
.machineId("myMachineId")
.beanFactory(new StaticListableBeanFactory())
.listener(new StateMachineListenerAdapter<States, Events>())
.transitionConflictPolicy(TransitionConflictPolicy.CHILD)
.regionExecutionPolicy(RegionExecutionPolicy.PARALLEL);
}
}
默认情况下,状态机的 autoStartup 标志是禁用的,因为所有处理子状态的实例都由状态机本身控制,无法自动启动。此外,将机器是否应自动启动的决定权交给用户更为安全。该标志仅控制顶级状态机的自动启动。
在配置类中设置 machineId 只是为了在您希望或需要在那里进行设置时提供便利。
注册 StateMachineListener 实例部分是为了方便,但如果你希望在状态机生命周期中捕获回调,例如获取状态机的启动和停止事件的通知,则是必需的。需要注意的是,如果启用了 autoStartup,你将无法监听状态机的启动事件,除非你在配置阶段注册了一个监听器。
当可以选择多个转换路径时,你可以使用 transitionConflictPolicy。一个常见的用例是当机器包含从子状态和父状态引出的匿名转换时,你希望定义一个策略来选择其中一个。这是机器实例中的全局设置,默认为 CHILD。
你可以使用 withDistributed() 来配置 DistributedStateMachine。它允许你设置一个 StateMachineEnsemble,如果存在的话,它会自动将任何创建的 StateMachine 包装为 DistributedStateMachine 并启用分布式模式。以下示例展示了如何使用它:
@Configuration
@EnableStateMachine
public class Config18
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineConfigurationConfigurer<States, Events> config)
throws Exception {
config
.withDistributed()
.ensemble(stateMachineEnsemble());
}
@Bean
public StateMachineEnsemble<States, Events> stateMachineEnsemble()
throws Exception {
// naturally not null but should return ensemble instance
return null;
}
}
有关分布式状态的更多信息,请参阅使用分布式状态。
StateMachineModelVerifier 接口在内部用于对状态机的结构进行一些健全性检查。其目的是尽早发现并处理问题,而不是让常见的配置错误进入状态机。默认情况下,验证器是自动启用的,并且使用 DefaultStateMachineModelVerifier 实现。
通过 withVerifier(),你可以禁用验证器或者在需要时设置一个自定义的验证器。以下示例展示了如何实现这一点:
@Configuration
@EnableStateMachine
public class Config19
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineConfigurationConfigurer<States, Events> config)
throws Exception {
config
.withVerifier()
.enabled(true)
.verifier(verifier());
}
@Bean
public StateMachineModelVerifier<States, Events> verifier() {
return new StateMachineModelVerifier<States, Events>() {
@Override
public void verify(StateMachineModel<States, Events> model) {
// throw exception indicating malformed model
}
};
}
}
有关配置模型的更多信息,请参阅 StateMachine 配置模型。
withSecurity、withMonitoring 和 withPersistence 配置方法分别在状态机安全、监控状态机和使用 StateMachineRuntimePersister中进行了文档说明。
配置模型
StateMachineModelFactory 是一个钩子,允许你在不使用手动配置的情况下配置一个状态机模型。本质上,它是一个第三方集成,用于集成到配置模型中。你可以通过使用 StateMachineModelConfigurer 将 StateMachineModelFactory 钩入配置模型。以下示例展示了如何做到这一点:
@Configuration
@EnableStateMachine
public static class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineModelConfigurer<String, String> model) throws Exception {
model
.withModel()
.factory(modelFactory());
}
@Bean
public StateMachineModelFactory<String, String> modelFactory() {
return new CustomStateMachineModelFactory();
}
}
以下示例使用 CustomStateMachineModelFactory 定义了两个状态(S1 和 S2)以及这两个状态之间的一个事件(E1):
public static class CustomStateMachineModelFactory implements StateMachineModelFactory<String, String> {
@Override
public StateMachineModel<String, String> build() {
ConfigurationData<String, String> configurationData = new ConfigurationData<>();
Collection<StateData<String, String>> stateData = new ArrayList<>();
stateData.add(new StateData<String, String>("S1", true));
stateData.add(new StateData<String, String>("S2"));
StatesData<String, String> statesData = new StatesData<>(stateData);
Collection<TransitionData<String, String>> transitionData = new ArrayList<>();
transitionData.add(new TransitionData<String, String>("S1", "S2", "E1"));
TransitionsData<String, String> transitionsData = new TransitionsData<>(transitionData);
StateMachineModel<String, String> stateMachineModel = new DefaultStateMachineModel<String, String>(configurationData,
statesData, transitionsData);
return stateMachineModel;
}
@Override
public StateMachineModel<String, String> build(String machineId) {
return build();
}
}
定义自定义模型通常不是人们所寻找的,尽管这是可行的。然而,允许外部访问此配置模型是一个核心概念。
你可以在 Eclipse Modeling Support 中找到使用此模型工厂集成的示例。你可以在 开发者文档 中找到关于自定义模型集成的更多通用信息。
需要记住的事项
在定义配置中的动作、守卫或其他引用时,记住 Spring Framework 如何处理 beans 是非常重要的。在下一个示例中,我们定义了一个包含状态 S1 和 S2 以及它们之间的四个转换的普通配置。所有转换都由 guard1 或 guard2 守卫。你必须确保 guard1 被创建为一个真正的 bean,因为它被 @Bean 注解标记,而 guard2 则没有。
这意味着事件 E3 将获得 guard2 条件为 TRUE,而 E4 将获得 guard2 条件为 FALSE,因为这些条件来自于对这些函数的普通方法调用。
然而,由于 guard1 被定义为 @Bean,它会被 Spring 框架代理。因此,对其方法的额外调用只会导致该实例的一次实例化。事件 E1 会首先获得带有条件 TRUE 的代理实例,而事件 E2 在方法调用定义为 FALSE 时,会获得相同的实例,但条件是 TRUE。这不是 Spring State Machine 特有的行为,而是 Spring 框架处理 bean 的方式。以下示例展示了这种安排是如何工作的:
@Configuration
@EnableStateMachine
public class Config1
extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("S1")
.state("S2");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("S1").target("S2").event("E1").guard(guard1(true))
.and()
.withExternal()
.source("S1").target("S2").event("E2").guard(guard1(false))
.and()
.withExternal()
.source("S1").target("S2").event("E3").guard(guard2(true))
.and()
.withExternal()
.source("S1").target("S2").event("E4").guard(guard2(false));
}
@Bean
public Guard<String, String> guard1(final boolean value) {
return new Guard<String, String>() {
@Override
public boolean evaluate(StateContext<String, String> context) {
return value;
}
};
}
public Guard<String, String> guard2(final boolean value) {
return new Guard<String, String>() {
@Override
public boolean evaluate(StateContext<String, String> context) {
return value;
}
};
}
}
状态机 ID
各种类和接口在方法中都将 machineId 用作变量或参数。本节将更详细地探讨 machineId 如何与正常机器操作和实例化相关联。
在运行时,machineId 除了用于区分不同的机器外,并没有太大的操作作用——例如,在跟踪日志或进行更深入的调试时。如果没有一种简单的方法来识别这些实例,开发者很快就会迷失在大量的不同机器实例中。因此,我们增加了设置 machineId 的选项。
使用 @EnableStateMachine
在 Java 配置中将 machineId 设置为 mymachine,然后在日志中暴露该值。同样的 machineId 也可以通过 StateMachine.getId() 方法获取。以下示例使用了 machineId 方法:
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withConfiguration()
.machineId("mymachine");
}
以下日志输出示例展示了 mymachine ID:
11:23:54,509 INFO main support.LifecycleObjectSupport [main] -
started S2 S1 / S1 / uuid=8fe53d34-8c85-49fd-a6ba-773da15fcaf1 / id=mymachine
手动构建器(参见通过构建器构建状态机)使用相同的配置接口,这意味着行为是等效的。
使用 @EnableStateMachineFactory
你可以看到相同的 machineId 被配置,如果你使用 StateMachineFactory 并通过该 ID 请求一个新的机器,如下例所示:
StateMachineFactory<String, String> factory = context.getBean(StateMachineFactory.class);
StateMachine<String, String> machine = factory.getStateMachine("mymachine");
使用 StateMachineModelFactory
在幕后,所有的机器配置首先被转换为一个 StateMachineModel,这样 StateMachineFactory 就不需要知道配置的来源,因为机器可以从 Java 配置、UML 或存储库中构建。如果你想要更灵活的控制,你也可以使用自定义的 StateMachineModel,这是定义配置的最低级别。
这些都与 machineId 有什么关系呢?StateMachineModelFactory 也有一个方法,其签名如下:StateMachineModel<S, E> build(String machineId),StateMachineModelFactory 的实现可以选择使用这个方法。
RepositoryStateMachineModelFactory(参见Repository 支持)使用 machineId 来通过 Spring Data Repository 接口支持持久化存储中的不同配置。例如,StateRepository 和 TransitionRepository 都有一个方法(List<T> findByMachineId(String machineId)),通过 machineId 来构建不同的状态和转换。使用 RepositoryStateMachineModelFactory 时,如果 machineId 为空或为 NULL,则默认为没有已知 machineId 的存储库配置(在持久化模型中)。
目前,UmlStateMachineModelFactory 不会区分不同的机器 ID,因为 UML 源始终来自同一个文件。这可能会在未来的版本中有所改变。
状态机工厂
在某些使用场景中,状态机需要动态创建,而不是在编译时通过定义静态配置来创建。例如,如果有一些自定义组件使用它们自己的状态机,并且这些组件是动态创建的,那么就无法在应用程序启动时构建一个静态的状态机。在内部,状态机始终通过工厂接口进行构建。这为开发者提供了以编程方式利用这一特性的选项。状态机工厂的配置与本文档中展示的各种示例中的状态机配置完全相同,其中状态机配置是硬编码的。
通过适配器的工厂
实际上,通过使用 @EnableStateMachine 创建状态机是通过工厂实现的,因此 @EnableStateMachineFactory 仅仅是通过其接口暴露了该工厂。以下示例使用了 @EnableStateMachineFactory:
@Configuration
@EnableStateMachineFactory
public class Config6
extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.S1)
.end(States.SF)
.states(EnumSet.allOf(States.class));
}
}
现在你已经使用了 @EnableStateMachineFactory 来创建一个工厂而不是一个状态机 bean,你可以注入它并使用它(原样)来请求新的状态机。以下示例展示了如何做到这一点:
public class Bean3 {
@Autowired
StateMachineFactory<States, Events> factory;
void method() {
StateMachine<States,Events> stateMachine = factory.getStateMachine();
stateMachine.startReactively().subscribe();
}
}
Adapter Factory 的局限性
当前工厂的限制是,所有与状态机关联的操作和守卫共享同一个实例。这意味着,从你的操作和守卫中,你需要特别处理同一个 bean 被不同状态机调用的情况。这一限制将在未来的版本中得到解决。
通过构建器实现状态机
使用适配器(如上所示)有一个限制,因为它需要通过 Spring 的 @Configuration 类和应用上下文来工作。虽然这是一个非常清晰的配置状态机的模型,但它限制了在编译时的配置,而这并不总是用户想要的做法。如果需要构建更动态的状态机,你可以使用一个简单的构建器模式来构造类似的实例。通过使用字符串作为状态和事件,你可以在 Spring 应用上下文之外使用这种构建器模式来构建完全动态的状态机。以下示例展示了如何做到这一点:
StateMachine<String, String> buildMachine1() throws Exception {
Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureStates()
.withStates()
.initial("S1")
.end("SF")
.states(new HashSet<String>(Arrays.asList("S1","S2","S3","S4")));
return builder.build();
}
构建器在幕后使用了与 @Configuration 模型相同的配置接口,这些接口用于适配器类。同样的模型也适用于通过构建器的方法来配置转换、状态和通用配置。这意味着,无论你在普通的 EnumStateMachineConfigurerAdapter 或 StateMachineConfigurerAdapter 中可以使用什么,都可以通过构建器动态地使用。
目前,builder.configureStates()、builder.configureTransitions() 和 builder.configureConfiguration() 接口方法无法链式调用,这意味着需要单独调用这些 builder 方法。
以下示例使用构建器设置了多个选项:
StateMachine<String, String> buildMachine2() throws Exception {
Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureConfiguration()
.withConfiguration()
.autoStartup(false)
.beanFactory(null)
.listener(null);
return builder.build();
}
你需要了解何时需要使用从构建器实例化的机器的常见配置。你可以使用 withConfiguration() 返回的配置器来设置 autoStart 和 BeanFactory。你也可以使用它来注册一个 StateMachineListener。如果通过 @Bean 将构建器返回的 StateMachine 实例注册为 bean,BeanFactory 会自动附加。如果你在 Spring 应用程序上下文之外使用实例,则必须使用这些方法来设置所需的设施。
使用延迟事件
当一个事件被发送时,它可能会触发一个 EventTrigger,如果状态机处于能够成功评估该触发器的状态,这可能会导致状态转换的发生。通常情况下,这可能会导致事件未被接受并被丢弃的情况。然而,你可能希望推迟该事件,直到状态机进入另一个状态。在这种情况下,你可以接受该事件。换句话说,事件在一个不合适的时机到达了。
Spring Statemachine 提供了一种机制,用于将事件推迟到以后处理。每个状态都可以有一个延迟事件列表。如果当前状态的延迟事件列表中的某个事件发生,该事件将被保存(延迟)以供将来处理,直到进入一个在其延迟事件列表中未列出该事件的状态。当进入这样的状态时,状态机会自动召回不再被延迟的任何保存事件,然后要么消费要么丢弃这些事件。一个超状态可能会定义一个在子状态中被延迟的事件的转换。遵循相同的层次状态机概念,子状态优先于超状态,事件被延迟,超状态的转换不会运行。在正交区域中,如果一个正交区域延迟了一个事件,而另一个正交区域接受了该事件,则接受优先,事件被消费而不会被延迟。
事件延迟最明显的使用场景是,当一个事件导致状态机转换到一个特定状态,然后状态机返回到其原始状态,此时第二个事件应导致相同的转换。以下示例展示了这种情况:
@Configuration
@EnableStateMachine
static class Config5 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("READY")
.state("DEPLOYPREPARE", "DEPLOY")
.state("DEPLOYEXECUTE", "DEPLOY");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("READY").target("DEPLOYPREPARE")
.event("DEPLOY")
.and()
.withExternal()
.source("DEPLOYPREPARE").target("DEPLOYEXECUTE")
.and()
.withExternal()
.source("DEPLOYEXECUTE").target("READY");
}
}
在前面的示例中,状态机有一个 READY 状态,表示机器已准备好处理事件,这些事件将使其进入 DEPLOY 状态,实际部署将在该状态下发生。在运行部署操作后,机器将返回到 READY 状态。如果机器使用同步执行器,在 READY 状态下发送多个事件不会引起任何问题,因为事件发送会在事件调用之间阻塞。然而,如果执行器使用线程,其他事件可能会丢失,因为机器不再处于可以处理事件的状态。因此,推迟其中的一些事件可以让机器保留它们。以下示例展示了如何配置这种安排:
@Configuration
@EnableStateMachine
static class Config6 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("READY")
.state("DEPLOY", "DEPLOY")
.state("DONE")
.and()
.withStates()
.parent("DEPLOY")
.initial("DEPLOYPREPARE")
.state("DEPLOYPREPARE", "DONE")
.state("DEPLOYEXECUTE");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("READY").target("DEPLOY")
.event("DEPLOY")
.and()
.withExternal()
.source("DEPLOYPREPARE").target("DEPLOYEXECUTE")
.and()
.withExternal()
.source("DEPLOYEXECUTE").target("READY")
.and()
.withExternal()
.source("READY").target("DONE")
.event("DONE")
.and()
.withExternal()
.source("DEPLOY").target("DONE")
.event("DONE");
}
}
在前面的示例中,状态机使用了嵌套状态而非扁平状态模型,因此 DEPLOY 事件可以直接在子状态中被延迟处理。该示例还展示了在子状态中延迟 DONE 事件的概念,如果状态机在 DONE 事件被派发时恰好处于 DEPLOYPREPARE 状态,那么该延迟将覆盖 DEPLOY 和 DONE 状态之间的匿名转换。而在 DEPLOYEXECUTE 状态中,如果 DONE 事件没有被延迟处理,该事件将在父状态中被处理。
使用作用域
在状态机中对 scope 的支持非常有限,但你可以通过以下两种方式之一使用普通的 Spring @Scope 注解来启用 session scope:
-
如果状态机是通过使用构建器手动构建并作为
@Bean返回到上下文中。 -
通过配置适配器。
这两者都需要 @Scope 注解,并且需要将 scopeName 设置为 session,同时将 proxyMode 设置为 ScopedProxyMode.TARGET_CLASS。以下示例展示了这两种使用场景:
@Configuration
public class Config3 {
@Bean
@Scope(scopeName="session", proxyMode=ScopedProxyMode.TARGET_CLASS)
StateMachine<String, String> stateMachine() throws Exception {
Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureConfiguration()
.withConfiguration()
.autoStartup(true);
builder.configureStates()
.withStates()
.initial("S1")
.state("S2");
builder.configureTransitions()
.withExternal()
.source("S1")
.target("S2")
.event("E1");
StateMachine<String, String> stateMachine = builder.build();
return stateMachine;
}
}
@Configuration
@EnableStateMachine
@Scope(scopeName="session", proxyMode=ScopedProxyMode.TARGET_CLASS)
public static class Config4 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config) throws Exception {
config
.withConfiguration()
.autoStartup(true);
}
@Override
public void configure(StateMachineStateConfigurer<String, String> states) throws Exception {
states
.withStates()
.initial("S1")
.state("S2");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions) throws Exception {
transitions
.withExternal()
.source("S1")
.target("S2")
.event("E1");
}
}
提示:有关如何使用会话作用域,请参阅作用域。
当你将一个状态机的作用域限定为 session 时,将其自动装配到 @Controller 中会为每个会话创建一个新的状态机实例。当 HttpSession 失效时,每个状态机都会被销毁。以下示例展示了如何在控制器中使用状态机:
@Controller
public class StateMachineController {
@Autowired
StateMachine<String, String> stateMachine;
@RequestMapping(path="/state", method=RequestMethod.POST)
public HttpEntity<Void> setState(@RequestParam("event") String event) {
stateMachine
.sendEvent(Mono.just(MessageBuilder
.withPayload(event).build()))
.subscribe();
return new ResponseEntity<Void>(HttpStatus.ACCEPTED);
}
@RequestMapping(path="/state", method=RequestMethod.GET)
@ResponseBody
public String getState() {
return stateMachine.getState().getId();
}
}
在 session 范围内使用状态机需要仔细规划,主要是因为它是一个相对较重的组件。
Spring Statemachine 的 poms 文件没有依赖 Spring MVC 类,而这些类是你需要使用 session 作用域时所需要的。不过,如果你正在开发一个 web 应用,你可能已经从 Spring MVC 或 Spring Boot 直接引入了这些依赖。
使用 Actions
Actions(动作)是你可以用来与状态机交互和协作的最有用的组件之一。你可以在状态机及其状态生命周期的多个位置运行动作——例如,进入或退出状态时,或在转换过程中。以下示例展示了如何在状态机中使用动作:
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.SI)
.state(States.S1, action1(), action2())
.state(States.S2, action1(), action2())
.state(States.S3, action1(), action3());
}
在前面的示例中,action1 和 action2 bean 分别附加到 entry 和 exit 状态。以下示例定义了这些动作(以及 action3):
@Bean
public Action<States, Events> action1() {
return new Action<States, Events>() {
@Override
public void execute(StateContext<States, Events> context) {
}
};
}
@Bean
public BaseAction action2() {
return new BaseAction();
}
@Bean
public SpelAction action3() {
ExpressionParser parser = new SpelExpressionParser();
return new SpelAction(
parser.parseExpression(
"stateMachine.sendEvent(T(org.springframework.statemachine.docs.Events).E1)"));
}
public class BaseAction implements Action<States, Events> {
@Override
public void execute(StateContext<States, Events> context) {
}
}
public class SpelAction extends SpelExpressionAction<States, Events> {
public SpelAction(Expression expression) {
super(expression);
}
}
你可以直接将 Action 实现为一个匿名函数,或者创建自己的实现并将其定义为一个 bean。
在前面的示例中,action3 使用了 SpEL 表达式将 Events.E1 事件发送到状态机中。
StateContext 在 使用 StateContext 中有详细描述。
带有 Actions 的 SpEL 表达式
你也可以使用 SpEL 表达式来替代完整的 Action 实现。
响应式操作
普通的 Action 接口是一个简单的函数方法,它接收 StateContext 并返回 void。在这里没有任何阻塞,除非你在方法内部进行了阻塞操作,而这会带来一些问题,因为框架无法确切知道方法内部发生了什么。
public interface Action<S, E> {
void execute(StateContext<S, E> context);
}
为了解决这个问题,我们在内部改变了 Action 的处理方式,使其处理一个普通的 Java Function,该函数接收 StateContext 并返回 Mono。通过这种方式,我们可以在完全响应式的方式下调用操作,并且只有在订阅时才会执行操作,同时以非阻塞的方式等待其完成。
public interface ReactiveAction<S, E> extends Function<StateContext<S, E>, Mono<Void>> {
}
在内部,旧的 Action 接口被包装为一个 Reactor Mono Runnable,因为它们共享相同的返回类型。我们无法控制你在该方法中做了什么!
使用 Guards
如 Things to Remember 所示,guard1 和 guard2 这两个 bean 分别附加到入口和出口状态。以下示例还在事件上使用了守卫:
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.SI).target(States.S1)
.event(Events.E1)
.guard(guard1())
.and()
.withExternal()
.source(States.S1).target(States.S2)
.event(Events.E1)
.guard(guard2())
.and()
.withExternal()
.source(States.S2).target(States.S3)
.event(Events.E2)
.guardExpression("extendedState.variables.get('myvar')");
}
你可以直接将 Guard 实现为一个匿名函数,或者创建你自己的实现并将其定义为一个 bean。在前面的示例中,guardExpression 检查名为 myvar 的扩展状态变量是否评估为 TRUE。以下示例实现了一些示例守卫:
@Bean
public Guard<States, Events> guard1() {
return new Guard<States, Events>() {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return true;
}
};
}
@Bean
public BaseGuard guard2() {
return new BaseGuard();
}
public class BaseGuard implements Guard<States, Events> {
@Override
public boolean evaluate(StateContext<States, Events> context) {
return false;
}
}
StateContext 在 使用 StateContext 部分中有详细描述。
带守卫的 SpEL 表达式
你也可以使用 SpEL 表达式来替代完整的 Guard 实现。唯一的要求是该表达式需要返回一个 Boolean 值以满足 Guard 实现。这可以通过一个接受表达式作为参数的 guardExpression() 函数来演示。
响应式守卫
普通的 Guard 接口是一个简单的函数式方法,它接收 StateContext 并返回一个 boolean 值。这里没有什么阻塞操作,直到你在方法内部进行阻塞,而这会带来一些问题,因为框架无法确切知道方法内部发生了什么。
public interface Guard<S, E> {
boolean evaluate(StateContext<S, E> context);
}
为了解决这个问题,我们在内部改变了 Guard 的处理方式,使其处理一个普通的 Java Function,该函数接收 StateContext 并返回 Mono<Boolean>。通过这种方式,我们可以在完全响应式的方式下调用 Guard,并且仅在订阅时对其进行评估,以非阻塞的方式等待完成并返回一个值。
public interface ReactiveGuard<S, E> extends Function<StateContext<S, E>, Mono<Boolean>> {
}
在内部,旧的 Guard 接口被封装在一个 Reactor Mono 函数中。我们无法控制你在该方法中执行的操作!
使用扩展状态
假设你需要创建一个状态机来跟踪用户按下键盘按键的次数,并在按键被按下 1000 次时终止。一个可能但非常天真的解决方案是为每 1000 次按键创建一个新的状态。你可能会突然拥有一个天文数字的状态数量,这显然不太实用。
这就是扩展状态变量发挥作用的地方,它不需要添加更多的状态来驱动状态机的变化。相反,你可以在状态转换期间简单地改变变量。
StateMachine 有一个名为 getExtendedState() 的方法。它返回一个名为 ExtendedState 的接口,该接口提供了对扩展状态变量的访问。你可以直接通过状态机或在动作或转换回调期间通过 StateContext 访问这些变量。以下示例展示了如何做到这一点:
public Action<String, String> myVariableAction() {
return new Action<String, String>() {
@Override
public void execute(StateContext<String, String> context) {
context.getExtendedState()
.getVariables().put("mykey", "myvalue");
}
};
}
如果你需要获取扩展状态变量变化的通知,你有两种选择:要么使用 StateMachineListener,要么监听 extendedStateChanged(key, value) 回调。以下示例使用了 extendedStateChanged 方法:
public class ExtendedStateVariableListener
extends StateMachineListenerAdapter<String, String> {
@Override
public void extendedStateChanged(Object key, Object value) {
// do something with changed variable
}
}
或者,你可以为 OnExtendedStateChanged 实现一个 Spring Application 上下文监听器。正如在 监听状态机事件 中提到的,你也可以监听所有的 StateMachineEvent 事件。以下示例使用 onApplicationEvent 来监听状态变化:
public class ExtendedStateVariableEventListener
implements ApplicationListener<OnExtendedStateChanged> {
@Override
public void onApplicationEvent(OnExtendedStateChanged event) {
// do something with changed variable
}
}
使用 StateContext
StateContext 是在使用状态机时最重要的对象之一,因为它被传递到各种方法和回调中,以提供状态机的当前状态及其可能的去向。你可以将其视为状态机当前阶段的快照,当 StateContext 被检索时,状态机正处于该阶段。
在 Spring Statemachine 1.0.x 中,StateContext 的使用相对简单,主要是作为一个简单的“POJO”来传递数据。从 Spring Statemachine 1.1.x 开始,它的角色得到了极大的提升,成为了状态机中的一等公民。
你可以使用 StateContext 来访问以下内容:
-
当前的
Message或Event(如果已知,包括它们的MessageHeaders)。 -
状态机的
Extended State。 -
StateMachine本身。 -
可能的状态机错误。
-
当前的
Transition(如果适用)。 -
状态机的源状态。
-
状态机的目标状态。
-
当前的
Stage,如 Stages 中所述。
StateContext 被传递到各种组件中,例如 Action 和 Guard。
阶段
触发过渡
驱动状态机是通过使用转换来完成的,这些转换由触发器触发。目前支持的触发器是 EventTrigger 和 TimerTrigger。
使用 EventTrigger
EventTrigger 是最有用的触发器,因为它允许你通过向状态机发送事件来直接与其交互。这些事件也被称为信号。你可以通过在配置期间将一个状态与触发器关联来向转换添加触发器。以下示例展示了如何做到这一点:
@Autowired
StateMachine<String, String> stateMachine;
void signalMachine() {
stateMachine
.sendEvent(Mono.just(MessageBuilder
.withPayload("E1").build()))
.subscribe();
Message<String> message = MessageBuilder
.withPayload("E2")
.setHeader("foo", "bar")
.build();
stateMachine.sendEvent(Mono.just(message)).subscribe();
}
无论你发送一个事件还是多个事件,结果总是一个结果序列。这是因为在存在多个区域的情况下,结果将从这些区域的多个机器返回。这通过方法 sendEventCollect 展示,它返回一个结果列表。该方法本身只是一个将 Flux 收集为列表的语法糖。如果只有一个区域,这个列表将包含一个结果。
Message<String> message1 = MessageBuilder
.withPayload("E1")
.build();
Mono<List<StateMachineEventResult<String, String>>> results =
stateMachine.sendEventCollect(Mono.just(message1));
results.subscribe();
在返回的 flux 被订阅之前,什么都不会发生。有关更多信息,请参阅 StateMachineEventResult。
前面的示例通过构造一个包装 Message 的 Mono 并订阅返回的 Flux 结果来发送事件。Message 允许我们向事件添加任意的额外信息,当(例如)你实现操作时,这些信息对 StateContext 是可见的。
消息头通常会一直传递,直到机器针对特定事件运行完成。例如,如果一个事件导致状态转换到状态 A,而状态 A 又有一个匿名转换到状态 B,那么在状态 B 中的动作或守卫中,原始事件仍然可用。
除了使用 Mono 发送单个消息外,也可以发送 Flux 的消息流。
Message<String> message1 = MessageBuilder
.withPayload("E1")
.build();
Message<String> message2 = MessageBuilder
.withPayload("E2")
.build();
Flux<StateMachineEventResult<String, String>> results =
stateMachine.sendEvents(Flux.just(message1, message2));
results.subscribe();
StateMachineEventResult
StateMachineEventResult 包含了关于事件发送结果的更详细信息。从中你可以获取到处理事件的 Region、Message 本身以及实际的 ResultType。通过 ResultType,你可以看到消息是被接受、拒绝还是延迟处理。一般来说,当订阅完成时,事件会被传递到状态机中。
使用 TimerTrigger
TimerTrigger 在需要自动触发某些操作而无需用户交互时非常有用。在配置过程中,通过将计时器与转换关联,可以将 Trigger 添加到转换中。
目前,支持两种类型的计时器:一种是连续触发的计时器,另一种是在进入源状态时触发的计时器。以下示例展示了如何使用触发器:
@Configuration
@EnableStateMachine
public class Config2 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("S1")
.state("S2")
.state("S3");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("S1").target("S2").event("E1")
.and()
.withExternal()
.source("S1").target("S3").event("E2")
.and()
.withInternal()
.source("S2")
.action(timerAction())
.timer(1000)
.and()
.withInternal()
.source("S3")
.action(timerAction())
.timerOnce(1000);
}
@Bean
public TimerAction timerAction() {
return new TimerAction();
}
}
public class TimerAction implements Action<String, String> {
@Override
public void execute(StateContext<String, String> context) {
// do something in every 1 sec
}
}
前面的示例有三个状态:S1、S2 和 S3。我们有一个从 S1 到 S2 和从 S1 到 S3 的正常外部转换,分别由事件 E1 和 E2 触发。与 TimerTrigger 相关的有趣部分是在我们为源状态 S2 和 S3 定义内部转换时。
对于这两个转换,我们调用了 Action bean(timerAction),其中源状态 S2 使用了 timer,而 S3 使用了 timerOnce。给定的值以毫秒为单位(两者均为 1000 毫秒,即一秒)。
当一个状态机接收到事件 E1 时,它会从状态 S1 转换到状态 S2,并启动计时器。当状态为 S2 时,TimerTrigger 会运行并触发与该状态关联的转换——在这种情况下,是定义了 timerAction 的内部转换。
当一个状态机接收到 E2 事件时,它会从 S1 状态转移到 S3 状态,并且计时器开始工作。这个计时器在进入状态后(在计时器定义的延迟之后)只执行一次。
在幕后,计时器是简单的触发器,可能会引起状态的转换。使用 timer() 定义的转换会不断触发,并且只有在源状态处于活动状态时才会引起转换。而使用 timerOnce() 的转换则略有不同,它只有在源状态实际进入后经过一定的延迟才会触发。
如果你想在状态进入时延迟执行某个操作且仅执行一次,请使用 timerOnce()。
监听状态机事件
在某些使用场景中,您可能希望了解状态机正在发生的情况,对某些事件做出反应,或者获取日志详细信息以用于调试目的。Spring Statemachine 提供了添加监听器的接口。这些监听器可以在各种状态变化、动作等发生时提供回调选项。
你基本上有两种选择:监听 Spring 应用上下文事件或直接为状态机附加监听器。这两种方式基本上提供相同的信息。一种是通过事件类生成事件,另一种是通过监听器接口生成回调。这两种方式各有优缺点,我们稍后会讨论。
应用上下文事件
应用程序上下文事件类包括 OnTransitionStartEvent、OnTransitionEvent、OnTransitionEndEvent、OnStateExitEvent、OnStateEntryEvent、OnStateChangedEvent、OnStateMachineStart、OnStateMachineStop 以及其他扩展了基础事件类 StateMachineEvent 的事件类。这些事件类可以直接与 Spring 的 ApplicationListener 一起使用。
StateMachine 通过 StateMachineEventPublisher 发送上下文事件。如果 @Configuration 类被 @EnableStateMachine 注解,默认实现会自动创建。以下示例从 @Configuration 类中定义的 bean 获取 StateMachineApplicationEventListener:
public class StateMachineApplicationEventListener
implements ApplicationListener<StateMachineEvent> {
@Override
public void onApplicationEvent(StateMachineEvent event) {
}
}
@Configuration
public class ListenerConfig {
@Bean
public StateMachineApplicationEventListener contextListener() {
return new StateMachineApplicationEventListener();
}
}
上下文事件也会通过使用 @EnableStateMachine 自动启用,其中 StateMachine 用于构建状态机并注册为一个 bean,如下例所示:
@Configuration
@EnableStateMachine
public class ManualBuilderConfig {
@Bean
public StateMachine<String, String> stateMachine() throws Exception {
Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureStates()
.withStates()
.initial("S1")
.state("S2");
builder.configureTransitions()
.withExternal()
.source("S1")
.target("S2")
.event("E1");
return builder.build();
}
}
使用 StateMachineListener
通过使用 StateMachineListener,你可以选择扩展它并实现所有的回调方法,或者使用 StateMachineListenerAdapter 类,该类包含了存根方法实现,你可以选择覆盖其中的部分方法。以下示例使用了后一种方法:
public class StateMachineEventListener
extends StateMachineListenerAdapter<States, Events> {
@Override
public void stateChanged(State<States, Events> from, State<States, Events> to) {
}
@Override
public void stateEntered(State<States, Events> state) {
}
@Override
public void stateExited(State<States, Events> state) {
}
@Override
public void transition(Transition<States, Events> transition) {
}
@Override
public void transitionStarted(Transition<States, Events> transition) {
}
@Override
public void transitionEnded(Transition<States, Events> transition) {
}
@Override
public void stateMachineStarted(StateMachine<States, Events> stateMachine) {
}
@Override
public void stateMachineStopped(StateMachine<States, Events> stateMachine) {
}
@Override
public void eventNotAccepted(Message<Events> event) {
}
@Override
public void extendedStateChanged(Object key, Object value) {
}
@Override
public void stateMachineError(StateMachine<States, Events> stateMachine, Exception exception) {
}
@Override
public void stateContext(StateContext<States, Events> stateContext) {
}
}
在前面的示例中,我们创建了自己的监听器类(StateMachineEventListener),它继承自 StateMachineListenerAdapter。
stateContext 监听器方法提供了在不同阶段访问各种 StateContext 变化的途径。你可以在 使用 StateContext 中了解更多相关信息。
一旦你定义了自己的监听器,你就可以使用 addStateListener 方法将其注册到状态机中。是在 Spring 配置中将其挂接,还是在应用程序生命周期的任何时刻手动挂接,这取决于个人偏好。以下示例展示了如何附加监听器:
public class Config7 {
@Autowired
StateMachine<States, Events> stateMachine;
@Bean
public StateMachineEventListener stateMachineEventListener() {
StateMachineEventListener listener = new StateMachineEventListener();
stateMachine.addStateListener(listener);
return listener;
}
}
限制与问题
Spring 应用上下文并不是最快的事件总线,因此我们建议仔细考虑状态机发送事件的速率。为了获得更好的性能,使用 StateMachineListener 接口可能会更好。出于这个特定的原因,你可以使用 @EnableStateMachine 和 @EnableStateMachineFactory 中的 contextEvents 标志来禁用 Spring 应用上下文事件,如前一节所示。以下示例展示了如何禁用 Spring 应用上下文事件:
@Configuration
@EnableStateMachine(contextEvents = false)
public class Config8
extends EnumStateMachineConfigurerAdapter<States, Events> {
}
@Configuration
@EnableStateMachineFactory(contextEvents = false)
public class Config9
extends EnumStateMachineConfigurerAdapter<States, Events> {
}
上下文集成
仅通过监听状态机的事件或使用状态和转换中的操作来进行交互,这种方式有些局限。有时候,这种方法在与状态机工作的应用程序创建交互时会显得过于局限和冗长。针对这种特定的使用场景,我们提供了一种 Spring 风格的上下文集成方式,可以轻松地将状态机功能注入到你的 beans 中。
可用的注解已经统一,以便能够访问与监听状态机事件中相同的状态机执行点。
你可以使用 @WithStateMachine 注解将状态机与现有的 bean 关联起来。然后你可以开始向该 bean 的方法添加支持的注解。以下示例展示了如何做到这一点:
@WithStateMachine
public class Bean1 {
@OnTransition
public void anyTransition() {
}
}
你也可以通过使用注解 name 字段从应用程序上下文中附加任何其他的状态机。以下示例展示了如何实现这一点:
@WithStateMachine(name = "myMachineBeanName")
public class Bean2 {
@OnTransition
public void anyTransition() {
}
}
有时,使用 machine id 会更加方便,这是你可以设置的一个标识符,以便更好地识别多个实例。这个 ID 映射到 StateMachine 接口中的 getId() 方法。以下示例展示了如何使用它:
@WithStateMachine(id = "myMachineId")
public class Bean16 {
@OnTransition
public void anyTransition() {
}
}
当使用 StateMachineFactory 生成状态机时,状态机使用动态提供的 id,bean 名称将默认为 stateMachine。由于 id 仅在运行时可知,因此无法使用 @WithStateMachine (id = "some-id")。
在这种情况下,使用 @WithStateMachine 或 @WithStateMachine(name = "stateMachine"),所有由工厂生成的状态机都将附加到你的 bean 或 beans 上。
你也可以将 @WithStateMachine 用作元注解,如前例所示。在这种情况下,你可以用 WithMyBean 来注解你的 bean。以下示例展示了如何做到这一点:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@WithStateMachine(name = "myMachineBeanName")
public @interface WithMyBean {
}
这些方法的返回类型无关紧要,实际上会被丢弃。
启用集成
你可以通过使用 @EnableWithStateMachine 注解来启用 @WithStateMachine 的所有功能,该注解会将所需的配置导入到 Spring 应用上下文中。@EnableStateMachine 和 @EnableStateMachineFactory 都已经标注了这个注解,因此不需要再次添加。然而,如果构建和配置状态机时没有使用配置适配器,则必须使用 @EnableWithStateMachine 以便在 @WithStateMachine 中使用这些功能。以下示例展示了如何操作:
public static StateMachine<String, String> buildMachine(BeanFactory beanFactory) throws Exception {
Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureConfiguration()
.withConfiguration()
.machineId("myMachineId")
.beanFactory(beanFactory);
builder.configureStates()
.withStates()
.initial("S1")
.state("S2");
builder.configureTransitions()
.withExternal()
.source("S1")
.target("S2")
.event("E1");
return builder.build();
}
@WithStateMachine(id = "myMachineId")
static class Bean17 {
@OnStateChanged
public void onStateChanged() {
}
}
如果一台机器没有被创建为一个 bean,你需要为该机器设置 BeanFactory,如前面的示例所示。否则,机器将无法感知调用你的 @WithStateMachine 方法的处理器。
方法参数
每个注解都支持完全相同的方法参数集合,但运行时行为会有所不同,这取决于注解本身以及被注解方法被调用的阶段。为了更好地理解上下文的工作原理,请参阅使用 StateContext。
有关方法参数之间的差异,请参阅本文档后面描述各个注解的部分。
实际上,所有注解方法都是通过使用 Spring SPel 表达式来调用的,这些表达式在过程中是动态构建的。为了使这一机制正常工作,这些表达式需要一个根对象(针对该对象进行评估)。这个根对象是一个 StateContext。我们还在内部进行了一些调整,以便可以直接访问 StateContext 方法,而无需通过上下文句柄。
最简单的参数类型就是 StateContext 本身。以下示例展示了如何使用它:
@WithStateMachine
public class Bean3 {
@OnTransition
public void anyTransition(StateContext<String, String> stateContext) {
}
}
你可以访问 StateContext 内容的其余部分。参数的数量和顺序并不重要。以下示例展示了如何访问 StateContext 内容的各个部分:
@WithStateMachine
public class Bean4 {
@OnTransition
public void anyTransition(
@EventHeaders Map<String, Object> headers,
@EventHeader("myheader1") Object myheader1,
@EventHeader(name = "myheader2", required = false) String myheader2,
ExtendedState extendedState,
StateMachine<String, String> stateMachine,
Message<String> message,
Exception e) {
}
}
你可以使用 @EventHeader 来绑定单个事件头,而不是使用 @EventHeaders 获取所有事件头。
过渡注解
过渡的注解包括 @OnTransition、@OnTransitionStart 和 @OnTransitionEnd。
这些注解的行为完全相同。为了展示它们的工作原理,我们展示如何使用 @OnTransition。在这个注解中,你可以使用 source 和 target 来限定一个转换。如果 source 和 target 留空,则匹配任何转换。以下示例展示了如何使用 @OnTransition 注解(记住 @OnTransitionStart 和 @OnTransitionEnd 的工作方式相同):
@WithStateMachine
public class Bean5 {
@OnTransition(source = "S1", target = "S2")
public void fromS1ToS2() {
}
@OnTransition
public void anyTransition() {
}
}
默认情况下,由于 Java 语言的限制,您无法将 @OnTransition 注解与您创建的状态和事件枚举一起使用。因此,您需要使用字符串表示形式。
此外,你可以通过向方法中添加所需的参数来访问 Event Headers 和 ExtendedState。然后,这些参数会自动调用该方法。以下示例展示了如何实现这一点:
@WithStateMachine
public class Bean6 {
@StatesOnTransition(source = States.S1, target = States.S2)
public void fromS1ToS2(@EventHeaders Map<String, Object> headers, ExtendedState extendedState) {
}
}
然而,如果你想要一个类型安全的注解,你可以创建一个新的注解并使用 @OnTransition 作为元注解。这个用户级别的注解可以引用实际的状态和事件枚举,框架会以相同的方式尝试匹配这些引用。以下示例展示了如何做到这一点:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@OnTransition
public @interface StatesOnTransition {
States[] source() default {};
States[] target() default {};
}
在前面的示例中,我们创建了一个 @StatesOnTransition 注解,它以类型安全的方式定义了 source 和 target。以下示例在一个 bean 中使用了该注解:
@WithStateMachine
public class Bean7 {
@StatesOnTransition(source = States.S1, target = States.S2)
public void fromS1ToS2() {
}
}
状态注解
以下是可用的状态注解:@OnStateChanged、@OnStateEntry 和 @OnStateExit。以下示例展示了如何使用 OnStateChanged 注解(其他两个注解的使用方式相同):
@WithStateMachine
public class Bean8 {
@OnStateChanged
public void anyStateChange() {
}
}
正如你可以使用转换注释一样,你可以定义目标状态和源状态。以下示例展示了如何做到这一点:
@WithStateMachine
public class Bean9 {
@OnStateChanged(source = "S1", target = "S2")
public void stateChangeFromS1toS2() {
}
}
为了类型安全,需要使用 @OnStateChanged 作为元注解为枚举创建新的注解。以下示例展示了如何操作:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@OnStateChanged
public @interface StatesOnStates {
States[] source() default {};
States[] target() default {};
}
@WithStateMachine
public class Bean10 {
@StatesOnStates(source = States.S1, target = States.S2)
public void fromS1ToS2() {
}
}
状态进入和退出的方法行为方式相同,如下例所示:
@WithStateMachine
public class Bean11 {
@OnStateEntry
public void anyStateEntry() {
}
@OnStateExit
public void anyStateExit() {
}
}
事件注解
有一个与事件相关的注解,名为 @OnEventNotAccepted。如果你指定了 event 属性,你可以监听特定事件未被接受的情况。如果你没有指定事件,你可以监听任何事件未被接受的情况。以下示例展示了使用 @OnEventNotAccepted 注解的两种方式:
@WithStateMachine
public class Bean12 {
@OnEventNotAccepted
public void anyEventNotAccepted() {
}
@OnEventNotAccepted(event = "E1")
public void e1EventNotAccepted() {
}
}
状态机注解
以下注解可用于状态机:@OnStateMachineStart、@OnStateMachineStop 和 @OnStateMachineError。
在状态机的启动和停止过程中,生命周期方法会被调用。以下示例展示了如何使用 @OnStateMachineStart 和 @OnStateMachineStop 来监听这些事件:
@WithStateMachine
public class Bean13 {
@OnStateMachineStart
public void onStateMachineStart() {
}
@OnStateMachineStop
public void onStateMachineStop() {
}
}
如果状态机因异常进入错误状态,@OnStateMachineStop 注解会被调用。以下示例展示了如何使用它:
@WithStateMachine
public class Bean14 {
@OnStateMachineError
public void onStateMachineError() {
}
}
扩展状态注解
有一个与扩展状态相关的注解。它名为 @OnExtendedStateChanged。你也可以只监听特定 key 的变化。以下示例展示了如何使用 @OnExtendedStateChanged,包括使用和不使用 key 属性的情况:
@WithStateMachine
public class Bean15 {
@OnExtendedStateChanged
public void anyStateChange() {
}
@OnExtendedStateChanged(key = "key1")
public void key1Changed() {
}
}
使用 StateMachineAccessor
StateMachine 是与状态机进行通信的主要接口。有时,你可能需要更动态和编程化地访问状态机及其嵌套状态机和区域的内部结构。对于这些用例,StateMachine 提供了一个名为 StateMachineAccessor 的功能接口,它提供了一个接口来访问各个 StateMachine 和 Region 实例。
StateMachineFunction 是一个简单的函数式接口,它允许你将 StateMachineAccess 接口应用于状态机。在 JDK 7 中,这些代码会显得有些冗长。然而,在 JDK 8 中使用 lambda 表达式时,代码相对简洁。
doWithAllRegions 方法提供了对状态机中所有 Region 实例的访问。以下示例展示了如何使用它:
stateMachine.getStateMachineAccessor().doWithAllRegions(function -> function.setRelay(stateMachine));
stateMachine.getStateMachineAccessor()
.doWithAllRegions(access -> access.setRelay(stateMachine));
doWithRegion 方法允许在状态机中访问单个 Region 实例。以下示例展示了如何使用它:
stateMachine.getStateMachineAccessor().doWithRegion(function -> function.setRelay(stateMachine));
stateMachine.getStateMachineAccessor()
.doWithRegion(access -> access.setRelay(stateMachine));
withAllRegions 方法提供了对状态机中所有 Region 实例的访问权限。以下示例展示了如何使用它:
for (StateMachineAccess<String, String> access : stateMachine.getStateMachineAccessor().withAllRegions()) {
access.setRelay(stateMachine);
}
stateMachine.getStateMachineAccessor().withAllRegions()
.stream().forEach(access -> access.setRelay(stateMachine));
withRegion 方法用于在状态机中访问单个 Region 实例。以下示例展示了如何使用它:
stateMachine.getStateMachineAccessor()
.withRegion().setRelay(stateMachine);
使用 StateMachineInterceptor
与使用 StateMachineListener 接口不同,你可以使用 StateMachineInterceptor。一个概念上的区别是,你可以使用拦截器来拦截并停止当前的状态变更,或者改变其转换逻辑。你不需要实现完整的接口,而是可以使用一个名为 StateMachineInterceptorAdapter 的适配器类来覆盖默认的空操作方法。
一个配方(持久化)和一个示例([statemachine-examples-persist])与使用拦截器相关。
你可以通过 StateMachineAccessor 注册一个拦截器。拦截器的概念是一个相对深层的内部特性,因此并没有直接通过 StateMachine 接口暴露出来。
以下示例展示了如何添加 StateMachineInterceptor 并重写所选方法:
stateMachine.getStateMachineAccessor()
.withRegion().addStateMachineInterceptor(new StateMachineInterceptor<String, String>() {
@Override
public Message<String> preEvent(Message<String> message, StateMachine<String, String> stateMachine) {
return message;
}
@Override
public StateContext<String, String> preTransition(StateContext<String, String> stateContext) {
return stateContext;
}
@Override
public void preStateChange(State<String, String> state, Message<String> message,
Transition<String, String> transition, StateMachine<String, String> stateMachine,
StateMachine<String, String> rootStateMachine) {
}
@Override
public StateContext<String, String> postTransition(StateContext<String, String> stateContext) {
return stateContext;
}
@Override
public void postStateChange(State<String, String> state, Message<String> message,
Transition<String, String> transition, StateMachine<String, String> stateMachine,
StateMachine<String, String> rootStateMachine) {
}
@Override
public Exception stateMachineError(StateMachine<String, String> stateMachine,
Exception exception) {
return exception;
}
});
有关前面示例中展示的错误处理的更多信息,请参阅状态机错误处理。
状态机安全
安全功能构建于 Spring Security 的功能之上。当需要保护状态机执行的一部分及其交互时,安全功能非常方便。
我们希望您对 Spring Security 有相当的了解,这意味着我们不会深入探讨整个安全框架的工作原理。有关这方面的信息,您应该阅读 Spring Security 参考文档(可在此处获取)。
安全的第一道防线自然是保护事件,这些事件真正驱动着状态机中将要发生的事情。然后,你可以为转换和动作定义更细粒度的安全设置。这类似于给员工访问建筑物的权限,然后赋予他们访问建筑物内特定房间的权限,甚至可以在特定房间内开关灯的能力。如果你信任你的用户,事件安全可能就是你所需要的。如果不信任,你需要应用更详细的安全措施。
你可以在理解安全性中找到更详细的信息。
完整示例请参见 Security 示例。
配置安全性
所有与安全相关的通用配置都在 SecurityConfigurer 中完成,该配置器从 StateMachineConfigurationConfigurer 中获取。默认情况下,即使存在 Spring Security 类,安全功能也是禁用的。以下示例展示了如何启用安全功能:
@Configuration
@EnableStateMachine
static class Config4 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withSecurity()
.enabled(true)
.transitionAccessDecisionManager(null)
.eventAccessDecisionManager(null);
}
}
如果你确实需要,你可以为事件和转换自定义 AccessDecisionManager。如果你没有定义决策管理器或将它们设置为 null,系统会在内部创建默认的管理器。
保护事件
事件安全性是在全局级别上通过 SecurityConfigurer 定义的。以下示例展示了如何启用事件安全性:
@Configuration
@EnableStateMachine
static class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withSecurity()
.enabled(true)
.event("true")
.event("ROLE_ANONYMOUS", ComparisonType.ANY);
}
}
在前面的配置示例中,我们使用了一个表达式 true,它总是评估为 TRUE。在实际应用中,使用总是评估为 TRUE 的表达式是没有意义的,但它展示了表达式需要返回 TRUE 或 FALSE 的观点。我们还定义了一个属性 ROLE_ANONYMOUS 和一个 ComparisonType 为 ANY。有关使用属性和表达式的更多信息,请参阅使用安全属性和表达式。
保护过渡
你可以在全局范围内定义过渡安全性,如下例所示。
@Configuration
@EnableStateMachine
static class Config6 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withSecurity()
.enabled(true)
.transition("true")
.transition("ROLE_ANONYMOUS", ComparisonType.ANY);
}
}
如果在转换本身中定义了安全性设置,它将覆盖任何全局设置的安全性。以下示例展示了如何实现这一点:
@Configuration
@EnableStateMachine
static class Config2 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("S0")
.target("S1")
.event("A")
.secured("ROLE_ANONYMOUS", ComparisonType.ANY)
.secured("hasTarget('S1')");
}
}
有关使用属性和表达式的更多信息,请参阅使用安全属性和表达式。
保护操作
在状态机中没有专门针对操作的安全定义,但你可以通过使用 Spring Security 的全局方法安全来保护操作。这要求将 Action 定义为一个代理的 @Bean,并在其 execute 方法上使用 @Secured 注解。以下示例展示了如何做到这一点:
@Configuration
@EnableStateMachine
static class Config3 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withSecurity()
.enabled(true);
}
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
states
.withStates()
.initial("S0")
.state("S1");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
transitions
.withExternal()
.source("S0")
.target("S1")
.action(securedAction())
.event("A");
}
@Scope(proxyMode = ScopedProxyMode.TARGET_CLASS)
@Bean
public Action<String, String> securedAction() {
return new Action<String, String>() {
@Secured("ROLE_ANONYMOUS")
@Override
public void execute(StateContext<String, String> context) {
}
};
}
}
需要在 Spring Security 中启用全局方法安全。以下示例展示了如何做到这一点:
@Configuration
public static class Config5 {
@Bean
public InMemoryUserDetailsManager userDetailsService() {
UserDetails user = User.withDefaultPasswordEncoder()
.username("user")
.password("password")
.roles("USER")
.build();
return new InMemoryUserDetailsManager(user);
}
}
详情请参阅 Spring Security 参考指南(可在此处获取)。
使用安全属性和表达式
通常,你可以通过两种方式定义安全属性:使用安全属性(security attributes)和使用安全表达式(security expressions)。属性使用起来更简单,但在功能上相对有限。表达式提供了更多的功能,但使用起来稍微复杂一些。
通用属性用法
默认情况下,AccessDecisionManager 实例用于事件和转换时都使用 RoleVoter,这意味着您可以使用来自 Spring Security 的角色属性。
对于属性,我们有三种不同的比较类型:ANY、ALL 和 MAJORITY。这些比较类型映射到默认的访问决策管理器(分别为 AffirmativeBased、UnanimousBased 和 ConsensusBased)。如果你定义了自定义的 AccessDecisionManager,比较类型实际上会被丢弃,因为它仅用于创建默认的管理器。
通用表达式用法
安全表达式必须返回 TRUE 或 FALSE。
表达式根对象的基类是 SecurityExpressionRoot。它提供了一些常见的表达式,这些表达式在转换和事件安全中都可用。下表描述了最常用的内置表达式:
表 1. 常见的内置表达式
| 表达式 | 描述 |
|---|---|
hasRole([role]) | 如果当前主体拥有指定的角色,则返回 true。默认情况下,如果提供的角色不以 ROLE_ 开头,则会自动添加。你可以通过修改 DefaultWebSecurityExpressionHandler 上的 defaultRolePrefix 来自定义此行为。 |
hasAnyRole([role1,role2]) | 如果当前主体拥有任何一个提供的角色(以逗号分隔的字符串列表形式给出),则返回 true。默认情况下,如果每个提供的角色不以 ROLE_ 开头,则会自动添加。你可以通过修改 DefaultWebSecurityExpressionHandler 上的 defaultRolePrefix 来自定义此行为。 |
hasAuthority([authority]) | 如果当前主体拥有指定的权限,则返回 true。 |
hasAnyAuthority([authority1,authority2]) | 如果当前主体拥有任何一个提供的权限(以逗号分隔的字符串列表形式给出),则返回 true。 |
principal | 允许直接访问表示当前用户的主体对象。 |
authentication | 允许直接访问从 SecurityContext 中获取的当前 Authentication 对象。 |
permitAll | 始终返回 true。 |
denyAll | 始终返回 false。 |
isAnonymous() | 如果当前主体是匿名用户,则返回 true。 |
isRememberMe() | 如果当前主体是 remember-me 用户,则返回 true。 |
isAuthenticated() | 如果用户不是匿名用户,则返回 true。 |
isFullyAuthenticated() | 如果用户既不是匿名用户也不是 remember-me 用户,则返回 true。 |
hasPermission(Object target, Object permission) | 如果用户对提供的目标拥有给定的权限,则返回 true — 例如,hasPermission(domainObject, 'read')。 |
hasPermission(Object targetId, String targetType, Object permission) | 如果用户对提供的目标拥有给定的权限,则返回 true — 例如,hasPermission(1, 'com.example.domain.Message', 'read')。 |
事件属性
你可以使用 EVENT_ 前缀来匹配事件 ID。例如,匹配事件 A 将会匹配属性 EVENT_A。
事件表达式
事件表达式根对象的基础类是 EventSecurityExpressionRoot。它提供了对 Message 对象的访问,该对象随事件一起传递。EventSecurityExpressionRoot 只有一个方法,下表描述了该方法:
表 2. 事件表达式
| 表达式 | 描述 |
|---|---|
hasEvent(Object event) | 如果事件与给定事件匹配,则返回 true。 |
过渡属性
在匹配转换源和目标时,可以分别使用 TRANSITION_SOURCE_ 和 TRANSITION_TARGET_ 前缀。
过渡表达式
用于转换的表达式根对象的基类是 TransitionSecurityExpressionRoot。它提供了对 Transition 对象的访问,该对象在转换更改时传递。TransitionSecurityExpressionRoot 有两个方法,下表描述了这些方法:
表 3. 过渡表达式
| 表达式 | 描述 |
|---|---|
hasSource(Object source) | 如果转换的源与给定的源匹配,则返回 true。 |
hasTarget(Object target) | 如果转换的目标与给定的目标匹配,则返回 true。 |
理解安全性
本节提供了关于状态机中安全机制如何运作的更详细信息。你可能并不真正需要了解这些内容,但透明地展示幕后发生的“魔法”总比隐藏它们要好。
安全性只有在 Spring Statemachine 运行在一个封闭的环境中才有意义,在这种环境中,用户无法直接访问应用程序,因此也无法修改 Spring Security 在本地线程中持有的 SecurityContext。如果用户控制了 JVM,那么实际上就根本不存在安全性。
安全集成的切入点是通过 StateMachineInterceptor 创建的,如果启用了安全功能,它会被自动添加到状态机中。具体的类是 StateMachineSecurityInterceptor,它会拦截事件和状态转换。然后,这个拦截器会咨询 Spring Security 的 AccessDecisionManager 来确定是否可以发送事件或执行状态转换。实际上,如果 AccessDecisionManager 的决策或投票导致异常,事件或状态转换将被拒绝。
由于 Spring Security 中的 AccessDecisionManager 的工作机制,我们需要为每个受保护的对象创建一个实例。这就是为什么事件和转换有不同的管理器的原因之一。在这种情况下,事件和转换是我们需要保护的不同类对象。
默认情况下,对于事件,投票者(EventExpressionVoter、EventVoter 和 RoleVoter)会被添加到 AccessDecisionManager 中。
默认情况下,对于过渡(transitions),投票者(TransitionExpressionVoter、TransitionVoter 和 RoleVoter)会被添加到 AccessDecisionManager 中。
状态机错误处理
如果状态机在状态转换逻辑期间检测到内部错误,它可能会抛出异常。在此异常被内部处理之前,您有机会进行拦截。
通常,你可以使用 StateMachineInterceptor 来拦截错误,下面的列表展示了一个示例:
StateMachine<String, String> stateMachine;
void addInterceptor() {
stateMachine.getStateMachineAccessor()
.doWithRegion(function ->
function.addStateMachineInterceptor(new StateMachineInterceptorAdapter<String, String>() {
@Override
public Exception stateMachineError(StateMachine<String, String> stateMachine,
Exception exception) {
return exception;
}
})
);
}
当检测到错误时,会执行正常的事件通知机制。这让你可以使用 StateMachineListener 或 Spring Application 上下文事件监听器。有关这些内容的更多信息,请参阅监听状态机事件。
话虽如此,以下示例展示了一个简单的监听器:
public class ErrorStateMachineListener
extends StateMachineListenerAdapter<String, String> {
@Override
public void stateMachineError(StateMachine<String, String> stateMachine, Exception exception) {
// do something with error
}
}
以下示例展示了一个通用的 ApplicationListener 检查 StateMachineEvent:
public class GenericApplicationEventListener
implements ApplicationListener<StateMachineEvent> {
@Override
public void onApplicationEvent(StateMachineEvent event) {
if (event instanceof OnStateMachineError) {
// do something with error
}
}
}
你也可以直接定义 ApplicationListener,使其仅识别 StateMachineEvent 实例,如下例所示:
public class ErrorApplicationEventListener
implements ApplicationListener<OnStateMachineError> {
@Override
public void onApplicationEvent(OnStateMachineError event) {
// do something with error
}
}
为转换定义的操作也有自己的错误处理逻辑。请参阅转换操作错误处理。
使用响应式 API,可以从 StateMachineEventResult 中获取 Action 执行错误。假设有一个简单的状态机,在转换到状态 S1 时,Action 中发生了错误。
@Configuration
@EnableStateMachine
static class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states) throws Exception {
states
.withStates()
.initial("SI")
.stateEntry("S1", (context) -> {
throw new RuntimeException("example error");
});
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions) throws Exception {
transitions
.withExternal()
.source("SI")
.target("S1")
.event("E1");
}
}
以下测试概念展示了如何从 StateMachineEventResult 中处理可能的错误。
@Autowired
private StateMachine<String, String> machine;
@Test
public void testActionEntryErrorWithEvent() throws Exception {
StepVerifier.create(machine.startReactively()).verifyComplete();
assertThat(machine.getState().getIds()).containsExactlyInAnyOrder("SI");
StepVerifier.create(machine.sendEvent(Mono.just(MessageBuilder.withPayload("E1").build())))
.consumeNextWith(result -> {
StepVerifier.create(result.complete()).consumeErrorWith(e -> {
assertThat(e).isInstanceOf(StateMachineException.class).cause().hasMessageContaining("example error");
}).verify();
})
.verifyComplete();
assertThat(machine.getState().getIds()).containsExactlyInAnyOrder("S1");
}
进入/退出动作中的错误不会阻止转换的发生。
状态机服务
StateMachine 服务是更高层次的实现,旨在提供更多用户级别的功能,以简化常规运行时操作。目前,仅存在一个服务接口(StateMachineService)。
使用 StateMachineService
StateMachineService 是一个接口,旨在处理运行中的机器,并提供简单的方法来“获取”和“释放”机器。它有一个默认的实现,名为 DefaultStateMachineService。
持久化状态机
传统上,状态机的实例在运行的程序中是直接使用的。你可以通过使用动态构建器和工厂来实现更动态的行为,这允许按需实例化状态机。构建一个状态机实例是一个相对较重的操作。因此,如果你需要(例如)通过使用状态机来处理数据库中的任意状态变化,你需要找到一个更好更快的方法来实现这一点。
持久化功能允许你将状态机的状态保存到外部存储库中,并随后根据序列化的状态重置状态机。例如,如果你有一个数据库表用于保存订单,若每次更改都需要构建一个新实例,使用状态机更新订单状态将非常昂贵。持久化功能使你可以重置状态机状态而无需实例化一个新的状态机实例。
这里有一个配方(参见 持久化)和一个示例(参见 [statemachine-examples-persist]),提供了关于状态持久化的更多信息。
虽然你可以通过使用 StateMachineListener 来构建自定义的持久化功能,但它存在一个概念上的问题。当监听器通知状态变化时,状态变化已经发生。如果监听器中的自定义持久化方法未能更新外部存储库中的序列化状态,那么状态机中的状态和外部存储库中的状态就会处于不一致的状态。
你可以改为使用状态机拦截器,在状态机内部的状态变化期间尝试将序列化状态保存到外部存储中。如果此拦截器回调失败,你可以暂停状态更改尝试,而不是以不一致的状态结束,然后手动处理此错误。有关如何使用拦截器,请参见使用 StateMachineInterceptor。
使用 StateMachineContext
你不能通过普通的 Java 序列化来持久化 StateMachine,因为对象图过于复杂,并且包含太多对其他 Spring 上下文类的依赖。StateMachineContext 是状态机的运行时表示,你可以使用它将现有的状态机恢复到由特定 StateMachineContext 对象表示的状态。
StateMachineContext 包含了两种不同的方式来包含子上下文的信息。这些方式通常用于包含正交区域的机器中。首先,一个上下文可以有一个子上下文列表,如果这些子上下文存在,可以直接使用。其次,你可以包含一个引用列表,如果原始上下文子项不存在,则使用这些引用。这些子引用实际上是持久化一个机器的唯一方式,其中多个并行区域独立运行。
数据多持久化示例展示了如何持久化并行区域。
使用 StateMachinePersister
手动构建 StateMachineContext 然后从中恢复状态机一直有点像是“黑魔法”。StateMachinePersister 接口旨在通过提供 persist 和 restore 方法来简化这些操作。该接口的默认实现是 DefaultStateMachinePersister。
我们可以通过测试中的代码片段来展示如何使用 StateMachinePersister。首先,我们为状态机创建两个相似的配置(machine1 和 machine2)。请注意,我们可以通过其他方式为这个演示构建不同的状态机,但这种方式适用于此场景。以下示例配置了两个状态机:
@Configuration
@EnableStateMachine(name = "machine1")
static class Config1 extends Config {
}
@Configuration
@EnableStateMachine(name = "machine2")
static class Config2 extends Config {
}
static class Config extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineStateConfigurer<String, String> states) throws Exception {
states
.withStates()
.initial("S1")
.state("S1")
.state("S2");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions) throws Exception {
transitions
.withExternal()
.source("S1")
.target("S2")
.event("E1");
}
}
由于我们正在使用 StateMachinePersist 对象,我们可以创建一个内存中的实现。
此内存示例仅用于演示目的。对于实际应用,您应该使用真实的持久化存储实现。
以下列表展示了如何使用内存中的示例:
static class InMemoryStateMachinePersist implements StateMachinePersist<String, String, String> {
private final HashMap<String, StateMachineContext<String, String>> contexts = new HashMap<>();
@Override
public void write(StateMachineContext<String, String> context, String contextObj) throws Exception {
contexts.put(contextObj, context);
}
@Override
public StateMachineContext<String, String> read(String contextObj) throws Exception {
return contexts.get(contextObj);
}
}
在我们实例化了两个不同的状态机之后,我们可以通过事件 E1 将 machine1 转移到状态 S2。然后我们可以将其持久化并恢复 machine2。以下示例展示了如何做到这一点:
InMemoryStateMachinePersist stateMachinePersist = new InMemoryStateMachinePersist();
StateMachinePersister<String, String, String> persister = new DefaultStateMachinePersister<>(stateMachinePersist);
StateMachine<String, String> stateMachine1 = context.getBean("machine1", StateMachine.class);
StateMachine<String, String> stateMachine2 = context.getBean("machine2", StateMachine.class);
stateMachine1.startReactively().block();
stateMachine1
.sendEvent(Mono.just(MessageBuilder
.withPayload("E1").build()))
.blockLast();
assertThat(stateMachine1.getState().getIds()).containsExactly("S2");
persister.persist(stateMachine1, "myid");
persister.restore(stateMachine2, "myid");
assertThat(stateMachine2.getState().getIds()).containsExactly("S2");
使用 Redis
RepositoryStateMachinePersist(实现了 StateMachinePersist)提供了将状态机持久化到 Redis 的支持。具体的实现是 RedisStateMachineContextRepository,它使用 kryo 序列化将 StateMachineContext 持久化到 Redis 中。
对于 StateMachinePersister,我们有一个与 Redis 相关的 RedisStateMachinePersister 实现,它接收一个 StateMachinePersist 的实例,并使用 String 作为其上下文对象。
有关详细用法,请参阅 事件服务 示例。
RedisStateMachineContextRepository 需要一个 RedisConnectionFactory 才能正常工作。我们建议使用 JedisConnectionFactory,如前面的示例所示。
使用 StateMachineRuntimePersister
StateMachineRuntimePersister 是 StateMachinePersist 的一个简单扩展,它添加了一个接口级方法,用于获取与其关联的 StateMachineInterceptor。然后,在状态变化期间需要持久化状态机时,这个拦截器是必需的,而无需停止和重新启动状态机。
目前,针对支持的 Spring Data Repositories,已经实现了该接口。这些实现包括 JpaPersistingStateMachineInterceptor、MongoDbPersistingStateMachineInterceptor 和 RedisPersistingStateMachineInterceptor。
有关详细用法,请参见 数据持久化 示例。
Spring Boot 支持
自动配置模块(spring-statemachine-autoconfigure)包含了与 Spring Boot 集成的所有逻辑,提供了自动配置和执行器的功能。你只需要将这个 Spring Statemachine 库作为 Spring Boot 应用程序的一部分即可。
监控与追踪
BootStateMachineMonitor 是自动创建并与状态机关联的。BootStateMachineMonitor 是一个自定义的 StateMachineMonitor 实现,它通过自定义的 StateMachineTraceRepository 与 Spring Boot 的 MeterRegistry 和端点集成。你可以通过将 spring.statemachine.monitor.enabled 键设置为 false 来禁用此自动配置。监控示例展示了如何使用此自动配置。
仓库配置
如果在类路径中找到了所需的类,Spring Data Repositories 和实体类扫描将自动为 Repository Support 进行自动配置。
当前支持的配置包括 JPA、Redis 和 MongoDB。你可以通过分别使用 spring.statemachine.data.jpa.repositories.enabled、spring.statemachine.data.redis.repositories.enabled 和 spring.statemachine.data.mongo.repositories.enabled 属性来禁用存储库的自动配置。
监控状态机
你可以使用 StateMachineMonitor 来获取有关转换和执行操作所需时间的更多信息。以下代码展示了如何实现这个接口。
public class TestStateMachineMonitor extends AbstractStateMachineMonitor<String, String> {
@Override
public void transition(StateMachine<String, String> stateMachine, Transition<String, String> transition,
long duration) {
}
@Override
public void action(StateMachine<String, String> stateMachine,
Function<StateContext<String, String>, Mono<Void>> action, long duration) {
}
}
一旦你有了一个 StateMachineMonitor 实现,你可以通过配置将其添加到状态机中,如下例所示:
@Configuration
@EnableStateMachine
public class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withMonitoring()
.monitor(stateMachineMonitor());
}
@Override
public void configure(StateMachineStateConfigurer<String, String> states) throws Exception {
states
.withStates()
.initial("S1")
.state("S2");
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions) throws Exception {
transitions
.withExternal()
.source("S1")
.target("S2")
.event("E1");
}
@Bean
public StateMachineMonitor<String, String> stateMachineMonitor() {
return new TestStateMachineMonitor();
}
}
有关详细用法,请参阅 监控 示例。
使用分布式状态
分布式状态可能是 Spring 状态机中最复杂的概念之一。那么,究竟什么是分布式状态?在单个状态机中的状态自然是非常容易理解的,但当你需要通过状态机引入共享的分布式状态时,事情就变得有些复杂了。
分布式状态功能仍处于预览阶段,在此特定版本中尚未被视为稳定。我们预计该功能将在首次正式发布时趋于成熟。
分布式状态机通过一个 DistributedStateMachine 类实现,该类封装了一个 StateMachine 的实际实例。DistributedStateMachine 拦截与 StateMachine 实例的通信,并通过 StateMachineEnsemble 接口处理分布式状态的抽象。根据实际实现,您还可以使用 StateMachinePersist 接口来序列化 StateMachineContext,其中包含足够的信息来重置 StateMachine。
虽然分布式状态机是通过抽象实现的,但目前只存在一种实现方式。它基于 Zookeeper。
以下示例展示了如何配置基于 Zookeeper 的分布式状态机`:
@Configuration
@EnableStateMachine
public class Config
extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineConfigurationConfigurer<String, String> config)
throws Exception {
config
.withDistributed()
.ensemble(stateMachineEnsemble())
.and()
.withConfiguration()
.autoStartup(true);
}
@Override
public void configure(StateMachineStateConfigurer<String, String> states)
throws Exception {
// config states
}
@Override
public void configure(StateMachineTransitionConfigurer<String, String> transitions)
throws Exception {
// config transitions
}
@Bean
public StateMachineEnsemble<String, String> stateMachineEnsemble()
throws Exception {
return new ZookeeperStateMachineEnsemble<String, String>(curatorClient(), "/zkpath");
}
@Bean
public CuratorFramework curatorClient()
throws Exception {
CuratorFramework client = CuratorFrameworkFactory
.builder()
.defaultData(new byte[0])
.connectString("localhost:2181").build();
client.start();
return client;
}
}
您可以在附录中找到基于 Zookeeper 的分布式状态机的当前技术文档。
使用 ZookeeperStateMachineEnsemble
ZookeeperStateMachineEnsemble 本身需要两个必需的设置,一个是 curatorClient 的实例,另一个是 basePath。客户端是一个 CuratorFramework,而路径是 Zookeeper 实例中树的根路径。
可选地,你可以设置 cleanState,它默认为 TRUE,如果集成中没有成员存在,则会清除现有数据。如果你想在应用程序重启时保留分布式状态,可以将其设置为 FALSE。
可选地,你可以设置 logSize 的大小(默认为 32)以保留状态更改的历史记录。此设置的值必须是 2 的幂次方。32 通常是一个不错的默认值。如果某个状态机的日志大小超过了设定的值,它将被置于错误状态,并从集群中断开连接,表明它已经丢失了历史记录并且无法完全重建同步状态。
测试支持
我们还添加了一组实用工具类,以简化状态机实例的测试。这些工具类在框架本身中使用,但对最终用户也非常有用。
StateMachineTestPlanBuilder 构建了一个 StateMachineTestPlan,该计划有一个方法(称为 test())。该方法用于运行一个计划。StateMachineTestPlanBuilder 包含一个流式构建器 API,允许你向计划中添加步骤。在这些步骤中,你可以发送事件并检查各种条件,例如状态变化、转换和扩展状态变量。
以下示例使用 StateMachineBuilder 来构建状态机:
private StateMachine<String, String> buildMachine() throws Exception {
StateMachineBuilder.Builder<String, String> builder = StateMachineBuilder.builder();
builder.configureConfiguration()
.withConfiguration()
.autoStartup(true);
builder.configureStates()
.withStates()
.initial("SI")
.state("S1");
builder.configureTransitions()
.withExternal()
.source("SI").target("S1")
.event("E1")
.action(c -> {
c.getExtendedState().getVariables().put("key1", "value1");
});
return builder.build();
}
在以下的测试计划中,我们有两个步骤。首先,我们检查初始状态(SI)是否确实被设置。其次,我们发送一个事件(E1),并期望发生一次状态变化,期望机器最终处于 S1 状态。以下列表展示了测试计划:
StateMachine<String, String> machine = buildMachine();
StateMachineTestPlan<String, String> plan =
StateMachineTestPlanBuilder.<String, String>builder()
.defaultAwaitTime(2)
.stateMachine(machine)
.step()
.expectStates("SI")
.and()
.step()
.sendEvent("E1")
.expectStateChanged(1)
.expectStates("S1")
.expectVariable("key1")
.expectVariable("key1", "value1")
.expectVariableWith(hasKey("key1"))
.expectVariableWith(hasValue("value1"))
.expectVariableWith(hasEntry("key1", "value1"))
.expectVariableWith(not(hasKey("key2")))
.and()
.build();
plan.test();
这些工具也用于在框架内测试分布式状态机功能。请注意,您可以在计划中添加多台机器。如果添加了多台机器,您还可以选择向特定机器、随机机器或所有机器发送事件。
前面的测试示例使用了以下 Hamcrest 导入:
import static org.hamcrest.CoreMatchers.not;
import static org.hamcrest.collection.IsMapContaining.hasKey;
import static org.hamcrest.collection.IsMapContaining.hasValue;
import org.junit.jupiter.api.Test;
import static org.hamcrest.collection.IsMapContaining.hasEntry;
所有可能的预期结果选项都记录在 StateMachineTestPlanStepBuilder 的 Javadoc 中。
Eclipse 建模支持
通过 Eclipse Papyrus 框架支持使用 UI 建模定义状态机配置。
在 Eclipse 向导中,你可以使用 UML 图语言创建一个新的 Papyrus 模型。在这个例子中,它被命名为 simple-machine。然后你可以选择各种图表类型,你必须选择一个 状态机图(StateMachine Diagram)。
我们想要创建一个具有两个状态(S1 和 S2)的机器,其中 S1 是初始状态。然后,我们需要创建事件 E1 来实现从 S1 到 S2 的转换。在 Papyrus 中,这样的机器看起来会像以下示例:
StateMachine {
State S1 (initial)
State S2
Transition T1 {
from: S1
to: S2
trigger: E1
}
}
在这个示例中,S1 是初始状态,S2 是另一个状态。通过事件 E1,机器可以从 S1 转换到 S2。
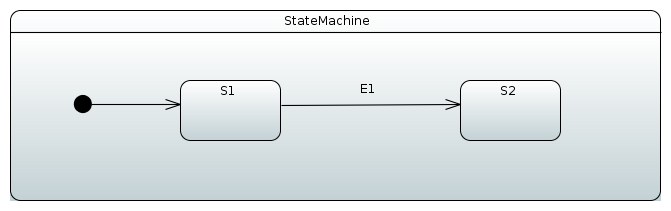
在幕后,一个原始的 UML 文件看起来会像以下示例:
<?xml version="1.0" encoding="UTF-8"?>
<uml:Model xmi:version="20131001" xmlns:xmi="http://www.omg.org/spec/XMI/20131001" xmlns:uml="http://www.eclipse.org/uml2/5.0.0/UML" xmi:id="_AMP3IP8fEeW45bORGB4c_A" name="RootElement">
<packagedElement xmi:type="uml:StateMachine" xmi:id="_AMRFQP8fEeW45bORGB4c_A" name="StateMachine">
<region xmi:type="uml:Region" xmi:id="_AMRsUP8fEeW45bORGB4c_A" name="Region1">
<transition xmi:type="uml:Transition" xmi:id="_chgcgP8fEeW45bORGB4c_A" source="_EZrg4P8fEeW45bORGB4c_A" target="_FAvg4P8fEeW45bORGB4c_A">
<trigger xmi:type="uml:Trigger" xmi:id="_hs5jUP8fEeW45bORGB4c_A" event="_NeH84P8fEeW45bORGB4c_A"/>
</transition>
<transition xmi:type="uml:Transition" xmi:id="_egLIoP8fEeW45bORGB4c_A" source="_Fg0IEP8fEeW45bORGB4c_A" target="_EZrg4P8fEeW45bORGB4c_A"/>
<subvertex xmi:type="uml:State" xmi:id="_EZrg4P8fEeW45bORGB4c_A" name="S1"/>
<subvertex xmi:type="uml:State" xmi:id="_FAvg4P8fEeW45bORGB4c_A" name="S2"/>
<subvertex xmi:type="uml:Pseudostate" xmi:id="_Fg0IEP8fEeW45bORGB4c_A"/>
</region>
</packagedElement>
<packagedElement xmi:type="uml:Signal" xmi:id="_L01D0P8fEeW45bORGB4c_A" name="E1"/>
<packagedElement xmi:type="uml:SignalEvent" xmi:id="_NeH84P8fEeW45bORGB4c_A" name="SignalEventE1" signal="_L01D0P8fEeW45bORGB4c_A"/>
</uml:Model>
当打开一个已定义为 UML 的现有模型时,你将拥有三个文件:.di、.notation 和 .uml。如果模型不是在当前 Eclipse 会话中创建的,Eclipse 将无法理解如何打开实际的状态图。这是 Papyrus 插件中的一个已知问题,但有一个简单的解决方法。在 Papyrus 视图中,你可以看到模型的模型资源管理器。双击 Diagram StateMachine Diagram,这将指示 Eclipse 在其适当的 Papyrus 建模插件中打开此特定模型。
使用 UmlStateMachineModelFactory
在你的项目中放置好 UML 文件后,你可以使用 StateMachineModelConfigurer 将其导入到配置中,其中 StateMachineModelFactory 与一个模型相关联。UmlStateMachineModelFactory 是一个特殊的工厂,它知道如何处理由 Eclipse Papyrus 生成的 UML 结构。源 UML 文件可以作为 Spring 的 Resource 提供,也可以作为普通的路径字符串提供。以下示例展示了如何创建 UmlStateMachineModelFactory 的实例:
@Configuration
@EnableStateMachine
public static class Config1 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineModelConfigurer<String, String> model) throws Exception {
model
.withModel()
.factory(modelFactory());
}
@Bean
public StateMachineModelFactory<String, String> modelFactory() {
return new UmlStateMachineModelFactory("classpath:org/springframework/statemachine/uml/docs/simple-machine.uml");
}
}
与往常一样,Spring Statemachine 与 guards 和 actions 一起工作,它们被定义为 beans。这些需要通过其内部建模结构挂接到 UML 中。以下部分展示了如何在 UML 定义中定义自定义的 bean 引用。请注意,也可以手动注册特定方法,而无需将它们定义为 beans。
如果 UmlStateMachineModelFactory 被创建为一个 bean,它的 ResourceLoader 会自动装配以查找已注册的动作(actions)和守卫(guards)。你也可以手动定义一个 StateMachineComponentResolver,然后它会被用来查找这些组件。工厂还提供了 registerAction 和 registerGuard 方法,你可以使用这些方法来注册这些组件。有关更多信息,请参阅 使用 StateMachineComponentResolver。
在实现方面,如 Spring Statemachine 本身,UML 模型相对较为宽松。Spring Statemachine 将许多特性和功能的实现方式留给了实际实现。接下来的部分将介绍 Spring Statemachine 如何基于 Eclipse Papyrus 插件实现 UML 模型。
使用 StateMachineComponentResolver
下一个示例展示了如何使用 StateMachineComponentResolver 来定义 UmlStateMachineModelFactory,并分别注册 myAction 和 myGuard 函数。请注意,这些组件并未作为 bean 创建。以下清单展示了该示例:
@Configuration
@EnableStateMachine
public static class Config2 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineModelConfigurer<String, String> model) throws Exception {
model
.withModel()
.factory(modelFactory());
}
@Bean
public StateMachineModelFactory<String, String> modelFactory() {
UmlStateMachineModelFactory factory = new UmlStateMachineModelFactory(
"classpath:org/springframework/statemachine/uml/docs/simple-machine.uml");
factory.setStateMachineComponentResolver(stateMachineComponentResolver());
return factory;
}
@Bean
public StateMachineComponentResolver<String, String> stateMachineComponentResolver() {
DefaultStateMachineComponentResolver<String, String> resolver = new DefaultStateMachineComponentResolver<>();
resolver.registerAction("myAction", myAction());
resolver.registerGuard("myGuard", myGuard());
return resolver;
}
public Action<String, String> myAction() {
return new Action<String, String>() {
@Override
public void execute(StateContext<String, String> context) {
}
};
}
public Guard<String, String> myGuard() {
return new Guard<String, String>() {
@Override
public boolean evaluate(StateContext<String, String> context) {
return false;
}
};
}
}
创建模型
我们首先创建一个空的状态机模型,如下图所示:
你可以通过创建一个新模型并为其命名开始,如下图所示:
然后你需要选择状态机图(StateMachine Diagram),如下所示:
你最终会得到一个空的状态机。
在前面的图片中,你应该已经创建了一个名为 model 的示例。最终你应该会得到三个文件:model.di、model.notation 和 model.uml。你可以在任何其他 Eclipse 实例中使用这些文件。此外,你还可以将 model.uml 导入到 Spring Statemachine 中。
定义状态
状态标识符来源于图表中的组件名称。你的状态机必须有一个初始状态,你可以通过添加一个根元素然后绘制一个过渡到你自己的初始状态来实现,如下图所示:
在前面的图像中,我们添加了一个根元素和一个初始状态(S1)。然后我们在两者之间绘制了一个过渡,以表示 S1 是一个初始状态。
在前面的图像中,我们添加了第二个状态(S2),并在 S1 和 S2 之间添加了一个过渡(表示我们有两个状态)。
定义事件
要将事件与转换关联,您需要创建一个信号(在本例中为 E1)。为此,选择 RootElement → New Child → Signal。下图显示了结果:
然后你需要使用新的 Signal E1 创建一个 SignalEvent。为此,选择 RootElement → New Child → SignalEvent。下图展示了结果:
现在你已经定义了一个 SignalEvent,你可以使用它来将触发器与转换关联起来。有关更多信息,请参阅定义转换。
延迟事件
你可以推迟事件以便在更合适的时间处理它们。在 UML 中,这是从状态本身完成的。选择任意状态,在可推迟触发器下创建一个新的触发器,并选择与你要推迟的 Signal 匹配的 SignalEvent。
定义转换
你可以通过在源状态和目标状态之间绘制一条过渡线来创建一个过渡。在前面的图像中,我们有状态 S1 和 S2,以及两者之间的一个匿名过渡。我们希望将事件 E1 与该过渡关联起来。我们选择一个过渡,创建一个新的触发器,并为其定义 SignalEventE1,如下图所示:
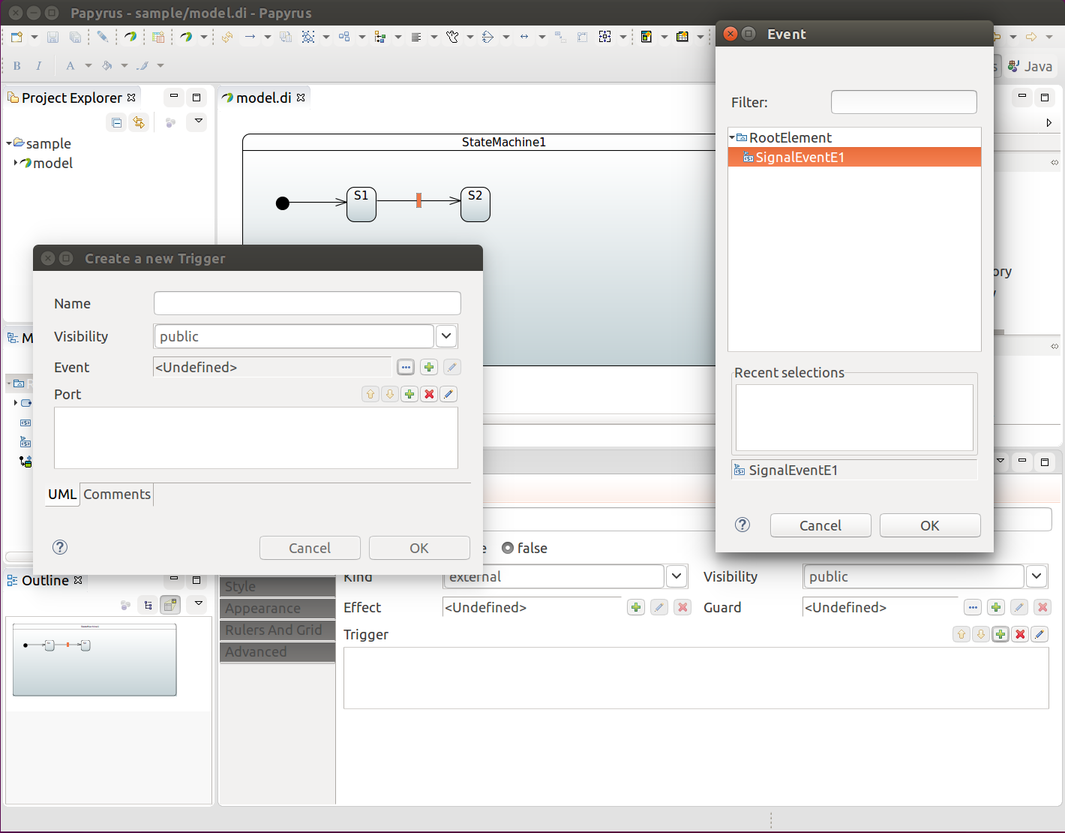
这将为你提供类似于下图所示的布局:
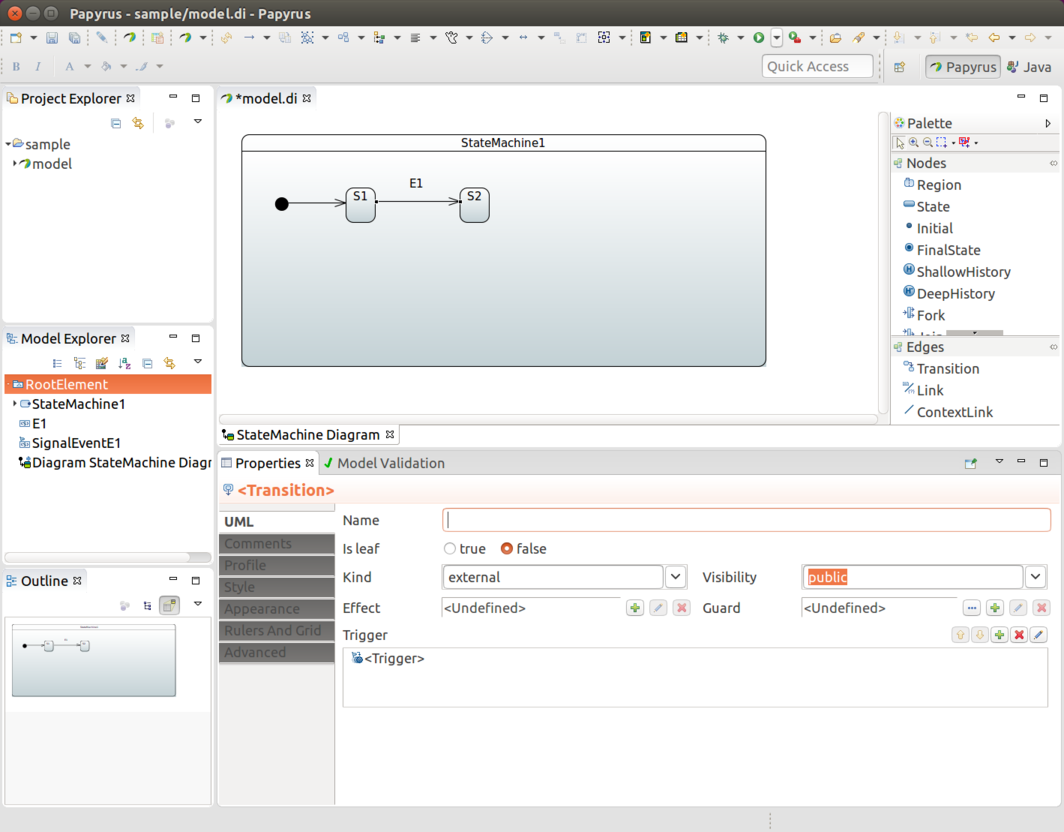
如果为一个过渡省略了 SignalEvent,它就会变成一个匿名过渡。
定义定时器
转换也可以基于定时事件发生。Spring Statemachine 支持两种类型的计时器:一种是在后台持续触发的计时器,另一种是在进入状态时延迟一次触发的计时器。
要在 Model Explorer 中添加一个新的 TimeEvent 子项,将 When 修改为定义为 LiteralInteger 的表达式。其值(以毫秒为单位)将成为计时器。将 Is Relative 保持为 false,以使计时器持续触发。
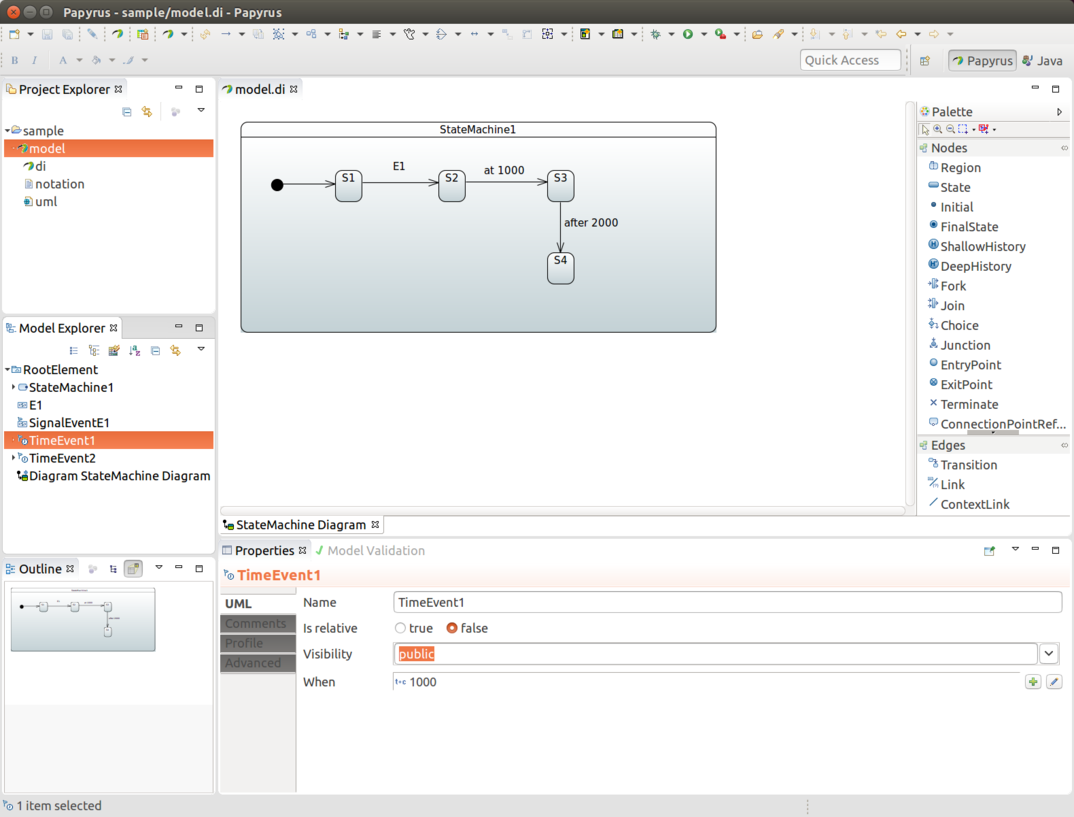
要定义一个基于时间的事件,该事件在进入某个状态时触发,其过程与前面描述的完全相同,但需将 Is Relative 保持为 true。下图显示了结果:
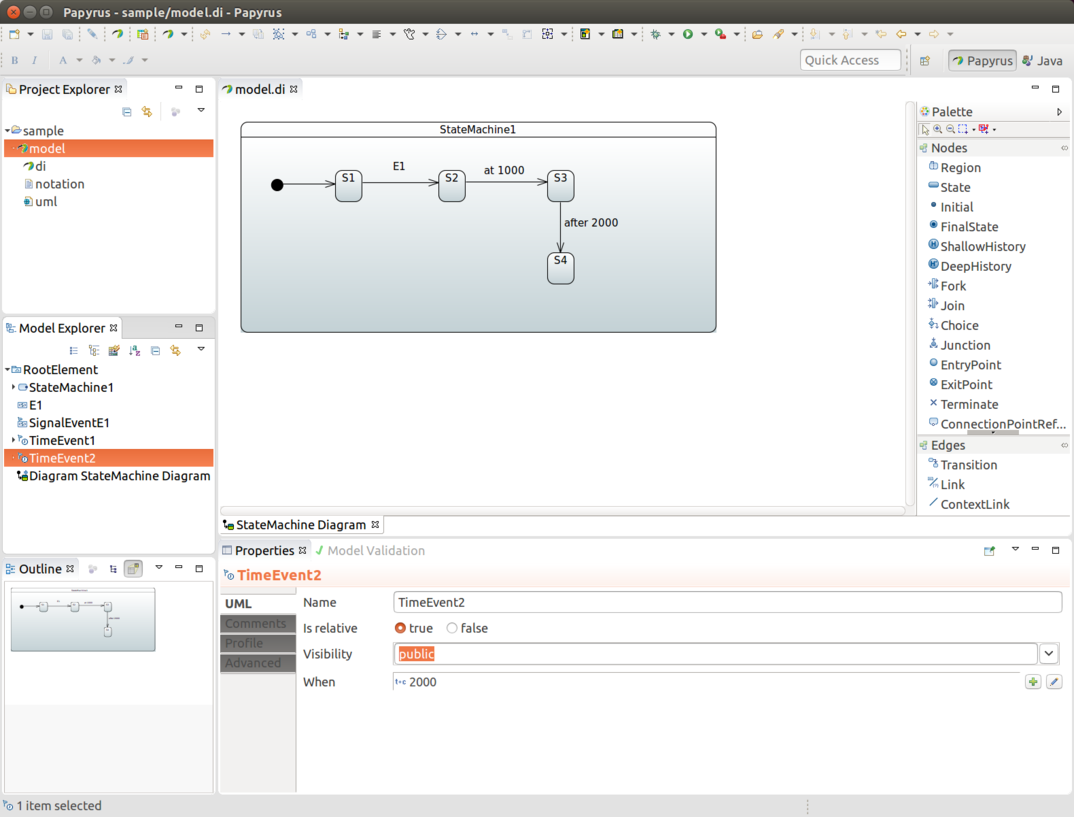
然后,用户可以为特定的转换选择一个定时事件,而不是信号事件。
定义选择
一个选择(choice)通过将一个传入转换绘制到 CHOICE 状态,并从该状态绘制多个传出转换到目标状态来定义。在我们的 StateConfigurer 中,配置模型允许你定义一个 if/elseif/else 结构。然而,使用 UML 时,我们需要为每个传出转换单独设置 Guard(守卫条件)。
你必须确保为转换定义的守卫(guards)不会重叠,以便无论发生什么情况,在任何给定时间只有一个守卫评估为 TRUE。这为选择分支评估提供了精确且可预测的结果。此外,我们建议保留一个没有守卫的转换,以确保至少有一个转换路径是保证的。下图展示了具有三个分支的选择结果:
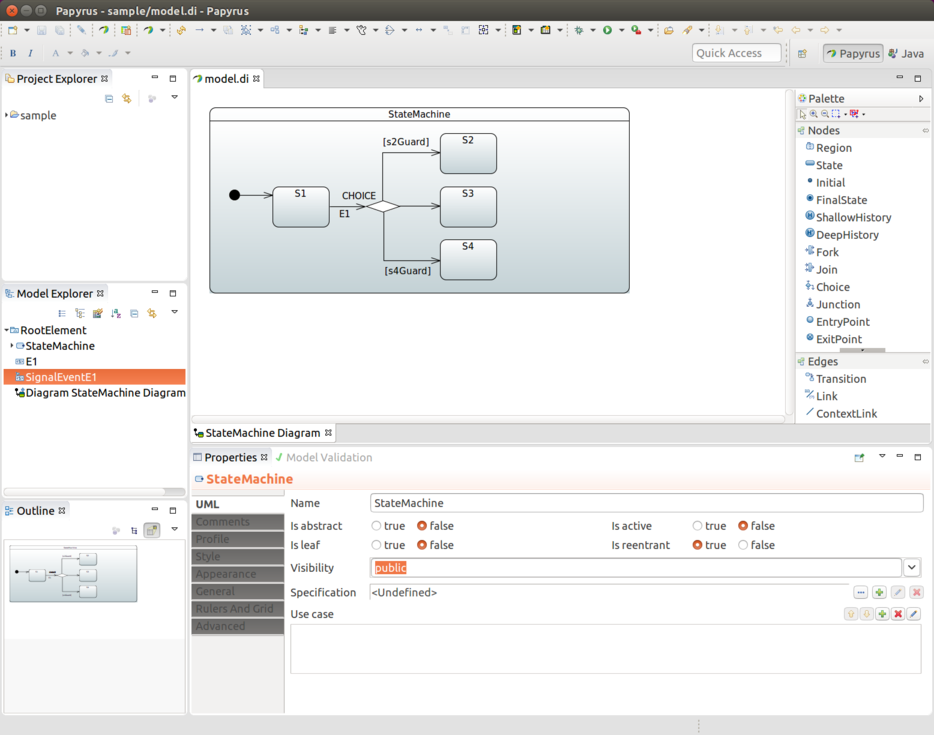
Junction 的工作方式与 Choice 类似,只是它允许多个传入的转换。因此,与 Choice 相比,它的行为纯粹是理论上的。选择传出转换的实际逻辑完全相同。
定义 Junction
请参阅定义选择。
定义入口和退出点
你可以使用 EntryPoint 和 ExitPoint 来创建具有子状态的状态的受控入口和出口。在以下状态图中,事件 E1 和 E2 通过进入和退出状态 S2 来执行正常的状态行为,而正常的状态行为是通过进入初始状态 S21 来完成的。
使用事件 E3 将机器带入 ENTRY 入口点,随后直接进入 S22,而不会在任何时候激活初始状态 S21。类似地,带有事件 E4 的 EXIT 出口点控制特定的退出行为,将机器带入状态 S4,而正常情况下从 S2 退出会将机器带入状态 S3。当处于状态 S22 时,你可以选择事件 E4 或 E2 分别将机器带入状态 S3 或 S4。下图展示了结果:
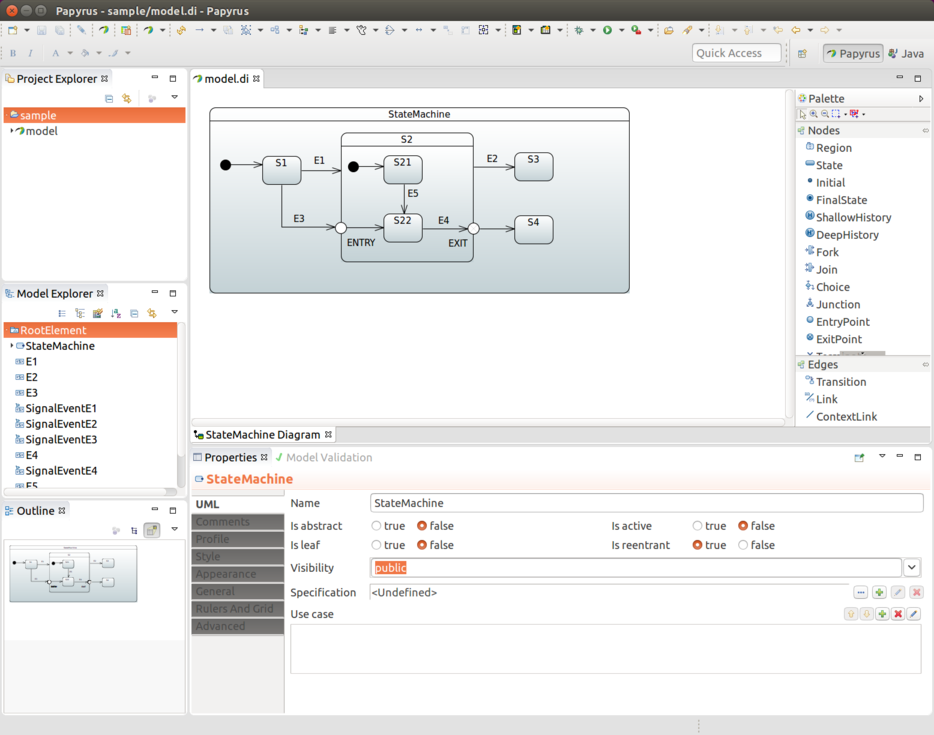
如果状态被定义为子机引用,并且你需要使用入口和出口点,你必须外部定义一个 ConnectionPointReference,将其入口和出口引用设置为指向子机引用内的正确入口或出口点。只有这样,才能正确地将转换从外部链接到子机引用的内部。使用 ConnectionPointReference 时,你可能需要从 Properties → Advanced → UML → Entry/Exit 中找到这些设置。UML 规范允许你定义多个入口和出口。然而,对于状态机,只允许一个入口和出口。
定义历史状态
在处理历史状态时,涉及三个不同的概念。UML 定义了深历史(Deep History)和浅历史(Shallow History)。当历史状态尚未确定时,默认历史状态(Default History State)会起作用。这些概念将在以下部分中进行说明。
浅历史
在下图中,选择了 Shallow History 并定义了进入它的转换:
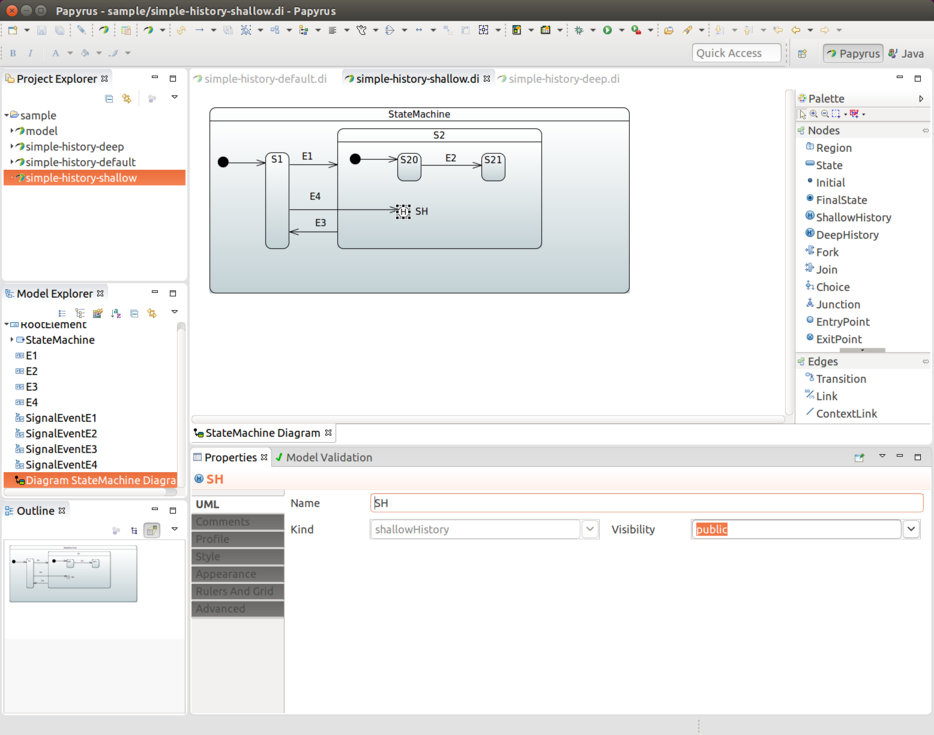
深度历史
Deep History 用于具有其他深层嵌套状态的状态,从而提供了保存整个嵌套状态结构的机会。下图展示了一个使用 Deep History 的定义:
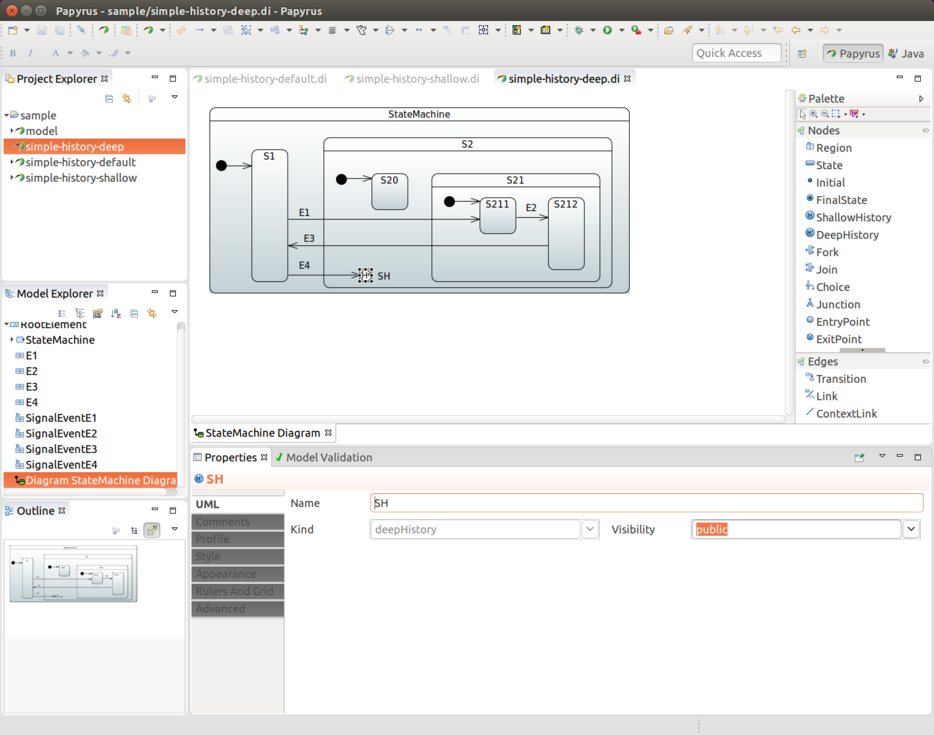
默认历史记录
在状态机中,如果某个 Transition 终止于一个历史状态,而该状态在其达到最终状态之前从未被进入过,可以使用默认历史机制强制跳转到一个特定的子状态。为了实现这一点,必须定义一个跳转到该默认状态的 Transition。例如,从 SH 到 S22 的跳转。
在下图中,如果状态 S2 从未被激活过,则进入状态 S22,因为其历史记录从未被记录。如果状态 S2 曾经被激活过,则选择 S20 或 S21。
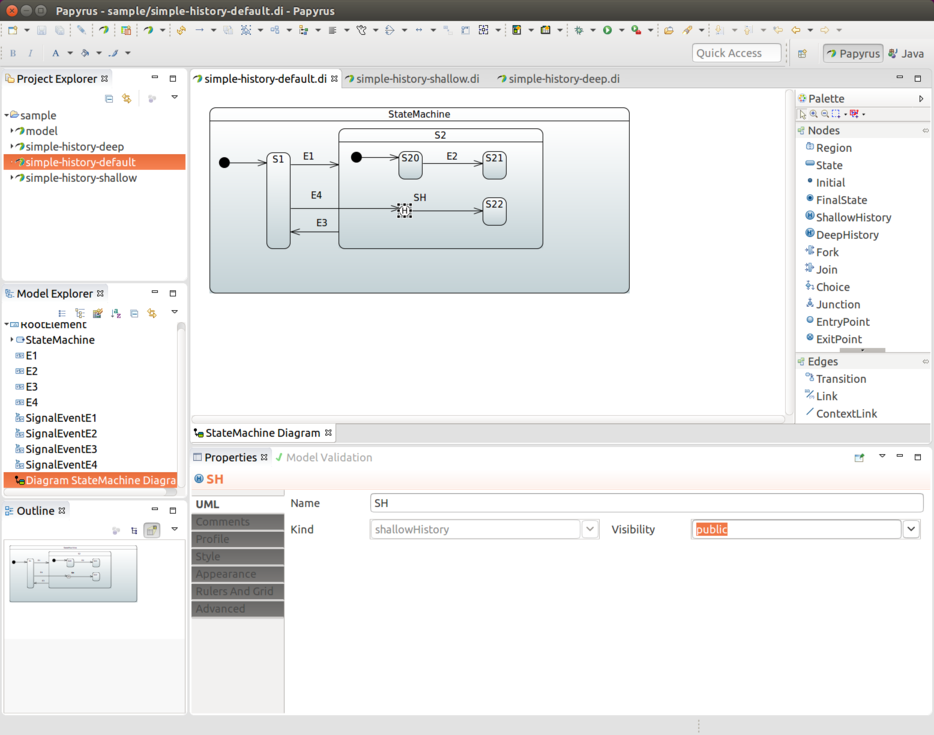
定义分支和合并
Fork 和 Join 在 Papyrus 中都表示为条形符号。如下图所示,你需要从 FORK 画一条向外的转换到状态 S2,以创建正交区域。JOIN 则是相反的操作,它将通过传入的转换将合并的状态收集在一起。
定义操作
你可以通过使用行为来关联状态的进入和退出动作。有关更多信息,请参阅定义 Bean 引用。
使用初始操作
在 UML 中,初始操作(如配置操作所示)是通过在从初始状态标记到实际状态的转换中添加一个操作来定义的。当状态机启动时,该操作将被执行。
定义 Guards
您可以通过首先添加一个 Constraint 来定义一个守卫,然后将其 Specification 定义为 OpaqueExpression,其工作方式与定义 Bean 引用相同。
定义 Bean 引用
当您需要在任何 UML 效果、动作或守卫中引用 bean 时,您可以使用 FunctionBehavior 或 OpaqueBehavior,其中定义的语言需要是 bean,并且语言体必须包含一个 bean 引用 ID。
定义 SpEL 引用
当您需要在任何 UML 效果、动作或守卫中使用 SpEL 表达式而不是 bean 引用时,您可以通过使用 FunctionBehavior 或 OpaqueBehavior 来实现,其中定义的语言需要设置为 spel,并且语言主体必须是一个 SpEL 表达式。
使用子机引用
通常,当你使用子状态时,你会将这些子状态绘制到状态图本身中。图表可能会变得过于复杂和庞大,难以跟踪,因此我们也支持将子状态定义为状态机引用。
要创建子状态机引用,您首先需要创建一个新的图表并为其命名(例如,SubStateMachine Diagram)。下图显示了使用的菜单选项:
为新图表设计所需样式。下图展示了一个简单的设计示例:
从你想要链接的状态(在本例中,状态 S2),点击 Submachine 字段并选择你要链接的机器(在我们的例子中,SubStateMachine)。
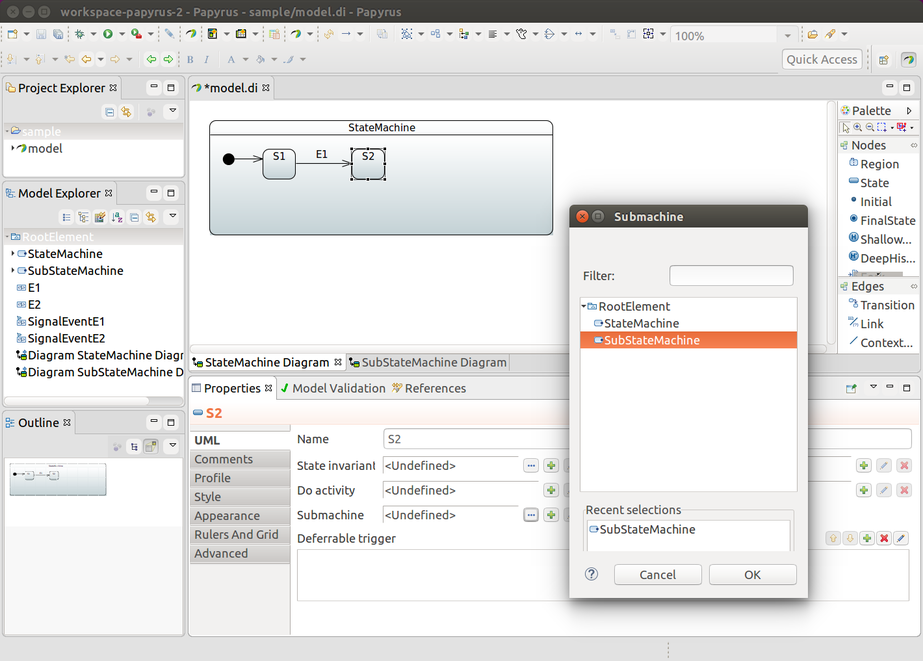
最后,在下图中,你可以看到状态 S2 被链接到 SubStateMachine 作为子状态。
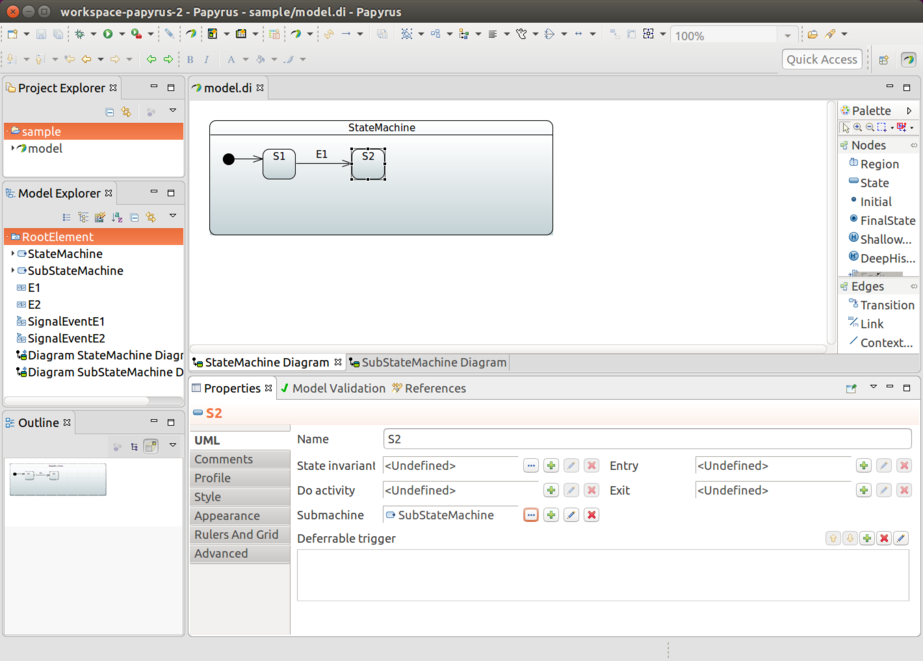
使用机器导入
也可以使用导入功能,其中 uml 文件可以引用其他模型。
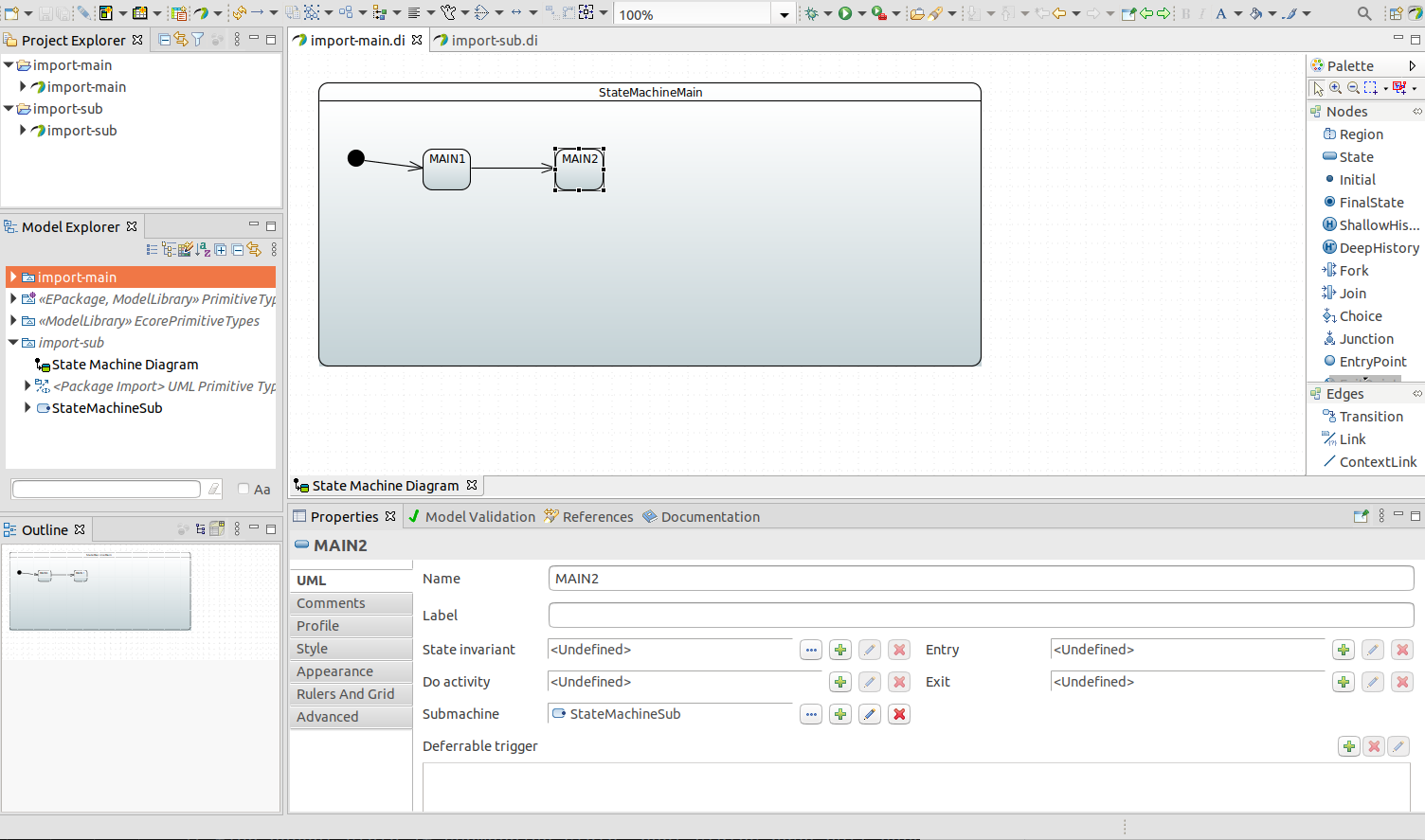
在 UmlStateMachineModelFactory 中,可以使用额外的资源或位置来定义引用的模型文件。
@Configuration
@EnableStateMachine
public static class Config3 extends StateMachineConfigurerAdapter<String, String> {
@Override
public void configure(StateMachineModelConfigurer<String, String> model) throws Exception {
model
.withModel()
.factory(modelFactory());
}
@Bean
public StateMachineModelFactory<String, String> modelFactory() {
return new UmlStateMachineModelFactory(
"classpath:org/springframework/statemachine/uml/import-main/import-main.uml",
new String[] { "classpath:org/springframework/statemachine/uml/import-sub/import-sub.uml" });
}
}
UML 模型中的文件链接需要是相对的,否则当模型文件从类路径复制到临时目录以便 Eclipse 解析类可以读取这些文件时,会导致问题。
仓库支持
本节包含与在 Spring Statemachine 中使用 'Spring Data Repositories' 相关的文档。
仓库配置
你可以将机器配置保存在外部存储中,以便按需加载,而不是通过使用 Java 配置或基于 UML 的配置来创建静态配置。这种集成通过 Spring Data Repository 抽象来实现。
我们创建了一个名为 RepositoryStateMachineModelFactory 的特殊 StateMachineModelFactory 实现。它可以使用基础仓库接口(StateRepository、TransitionRepository、ActionRepository 和 GuardRepository)以及基础实体接口(RepositoryState、RepositoryTransition、RepositoryAction 和 RepositoryGuard)。
由于 Spring Data 中实体和仓库的工作方式,从用户的角度来看,读取访问可以完全抽象化,就像在 RepositoryStateMachineModelFactory 中所做的那样。用户不需要知道仓库实际映射的实体类。写入仓库则总是依赖于使用特定于仓库的实际实体类。从机器配置的角度来看,我们不需要知道这些,也就是说,我们不需要知道实际的实现是 JPA、Redis 还是 Spring Data 支持的其他任何东西。当你手动尝试将新状态或转换写入支持的仓库时,使用实际的与仓库相关的实体类才会发挥作用。
RepositoryState 和 RepositoryTransition 的实体类包含一个 machineId 字段,该字段由您支配,可用于区分不同的配置——例如,如果机器是通过 StateMachineFactory 构建的。
实际实现将在后续章节中详细说明。以下图像是仓库配置的 UML 等效状态图。
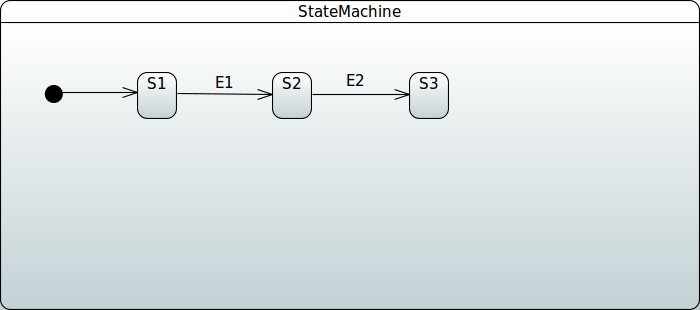
图 1. SimpleMachine
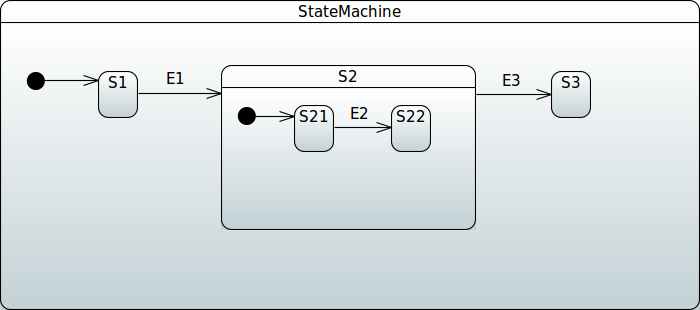
图 2. SimpleSubMachine
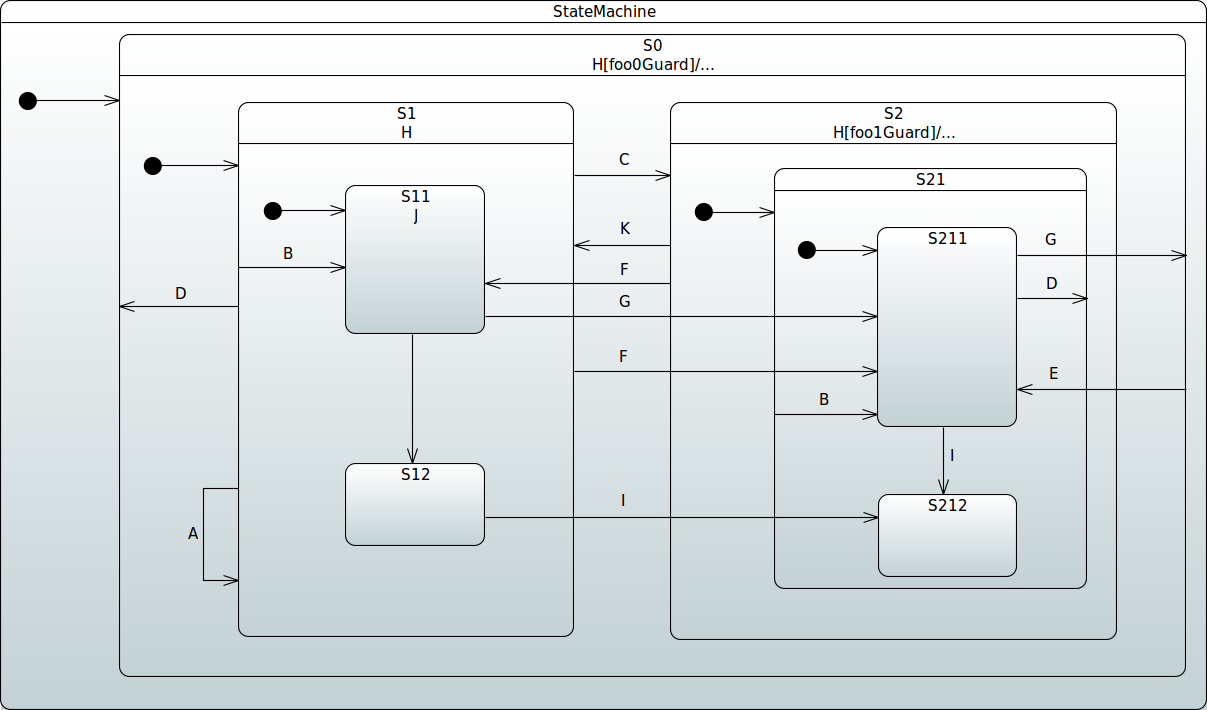
图 3. ShowcaseMachine
JPA
JPA 的实际存储库实现包括 JpaStateRepository、JpaTransitionRepository、JpaActionRepository 和 JpaGuardRepository,它们分别由实体类 JpaRepositoryState、JpaRepositoryTransition、JpaRepositoryAction 和 JpaRepositoryGuard 支持。
不幸的是,版本 '1.2.8' 不得不对 JPA 的实体模型中使用的表名进行更改。以前,生成的表名总是有一个前缀 JPA_REPOSITORY_,该前缀来源于实体类名称。由于这导致了与数据库对象长度限制相关的破坏性问题,所有实体类现在都有特定的定义来强制表名。例如,JPA_REPOSITORY_STATE 现在改为 'STATE',其他实体类也依此类推。
以下示例展示了手动更新 JPA 状态和转换的通用方法(等同于 SimpleMachine 中展示的机器):
@Autowired
StateRepository<JpaRepositoryState> stateRepository;
@Autowired
TransitionRepository<JpaRepositoryTransition> transitionRepository;
void addConfig() {
JpaRepositoryState stateS1 = new JpaRepositoryState("S1", true);
JpaRepositoryState stateS2 = new JpaRepositoryState("S2");
JpaRepositoryState stateS3 = new JpaRepositoryState("S3");
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
JpaRepositoryTransition transitionS1ToS2 = new JpaRepositoryTransition(stateS1, stateS2, "E1");
JpaRepositoryTransition transitionS2ToS3 = new JpaRepositoryTransition(stateS2, stateS3, "E2");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
}
以下示例也等同于 SimpleSubMachine 中展示的机器。
@Autowired
StateRepository<JpaRepositoryState> stateRepository;
@Autowired
TransitionRepository<JpaRepositoryTransition> transitionRepository;
void addConfig() {
JpaRepositoryState stateS1 = new JpaRepositoryState("S1", true);
JpaRepositoryState stateS2 = new JpaRepositoryState("S2");
JpaRepositoryState stateS3 = new JpaRepositoryState("S3");
JpaRepositoryState stateS21 = new JpaRepositoryState("S21", true);
stateS21.setParentState(stateS2);
JpaRepositoryState stateS22 = new JpaRepositoryState("S22");
stateS22.setParentState(stateS2);
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
stateRepository.save(stateS21);
stateRepository.save(stateS22);
JpaRepositoryTransition transitionS1ToS2 = new JpaRepositoryTransition(stateS1, stateS2, "E1");
JpaRepositoryTransition transitionS2ToS3 = new JpaRepositoryTransition(stateS21, stateS22, "E2");
JpaRepositoryTransition transitionS21ToS22 = new JpaRepositoryTransition(stateS2, stateS3, "E3");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
transitionRepository.save(transitionS21ToS22);
}
首先,你必须访问所有仓库。以下示例展示了如何操作:
@Autowired
StateRepository<JpaRepositoryState> stateRepository;
@Autowired
TransitionRepository<JpaRepositoryTransition> transitionRepository;
@Autowired
ActionRepository<JpaRepositoryAction> actionRepository;
@Autowired
GuardRepository<JpaRepositoryGuard> guardRepository;
其次,你必须创建 actions 和 guards。以下示例展示了如何做到这一点:
JpaRepositoryGuard foo0Guard = new JpaRepositoryGuard();
foo0Guard.setName("foo0Guard");
JpaRepositoryGuard foo1Guard = new JpaRepositoryGuard();
foo1Guard.setName("foo1Guard");
JpaRepositoryAction fooAction = new JpaRepositoryAction();
fooAction.setName("fooAction");
guardRepository.save(foo0Guard);
guardRepository.save(foo1Guard);
actionRepository.save(fooAction);
第三,你必须创建状态。以下示例展示了如何做到这一点:
JpaRepositoryState stateS0 = new JpaRepositoryState("S0", true);
stateS0.setInitialAction(fooAction);
JpaRepositoryState stateS1 = new JpaRepositoryState("S1", true);
stateS1.setParentState(stateS0);
JpaRepositoryState stateS11 = new JpaRepositoryState("S11", true);
stateS11.setParentState(stateS1);
JpaRepositoryState stateS12 = new JpaRepositoryState("S12");
stateS12.setParentState(stateS1);
JpaRepositoryState stateS2 = new JpaRepositoryState("S2");
stateS2.setParentState(stateS0);
JpaRepositoryState stateS21 = new JpaRepositoryState("S21", true);
stateS21.setParentState(stateS2);
JpaRepositoryState stateS211 = new JpaRepositoryState("S211", true);
stateS211.setParentState(stateS21);
JpaRepositoryState stateS212 = new JpaRepositoryState("S212");
stateS212.setParentState(stateS21);
stateRepository.save(stateS0);
stateRepository.save(stateS1);
stateRepository.save(stateS11);
stateRepository.save(stateS12);
stateRepository.save(stateS2);
stateRepository.save(stateS21);
stateRepository.save(stateS211);
stateRepository.save(stateS212);
第四点,也是最后一点,你必须创建过渡效果。以下示例展示了如何实现这一点:
JpaRepositoryTransition transitionS1ToS1 = new JpaRepositoryTransition(stateS1, stateS1, "A");
transitionS1ToS1.setGuard(foo1Guard);
JpaRepositoryTransition transitionS1ToS11 = new JpaRepositoryTransition(stateS1, stateS11, "B");
JpaRepositoryTransition transitionS21ToS211 = new JpaRepositoryTransition(stateS21, stateS211, "B");
JpaRepositoryTransition transitionS1ToS2 = new JpaRepositoryTransition(stateS1, stateS2, "C");
JpaRepositoryTransition transitionS1ToS0 = new JpaRepositoryTransition(stateS1, stateS0, "D");
JpaRepositoryTransition transitionS211ToS21 = new JpaRepositoryTransition(stateS211, stateS21, "D");
JpaRepositoryTransition transitionS0ToS211 = new JpaRepositoryTransition(stateS0, stateS211, "E");
JpaRepositoryTransition transitionS1ToS211 = new JpaRepositoryTransition(stateS1, stateS211, "F");
JpaRepositoryTransition transitionS2ToS21 = new JpaRepositoryTransition(stateS2, stateS21, "F");
JpaRepositoryTransition transitionS11ToS211 = new JpaRepositoryTransition(stateS11, stateS211, "G");
JpaRepositoryTransition transitionS0 = new JpaRepositoryTransition(stateS0, stateS0, "H");
transitionS0.setKind(TransitionKind.INTERNAL);
transitionS0.setGuard(foo0Guard);
transitionS0.setActions(new HashSet<>(Arrays.asList(fooAction)));
JpaRepositoryTransition transitionS1 = new JpaRepositoryTransition(stateS1, stateS1, "H");
transitionS1.setKind(TransitionKind.INTERNAL);
JpaRepositoryTransition transitionS2 = new JpaRepositoryTransition(stateS2, stateS2, "H");
transitionS2.setKind(TransitionKind.INTERNAL);
transitionS2.setGuard(foo1Guard);
transitionS2.setActions(new HashSet<>(Arrays.asList(fooAction)));
JpaRepositoryTransition transitionS11ToS12 = new JpaRepositoryTransition(stateS11, stateS12, "I");
JpaRepositoryTransition transitionS12ToS212 = new JpaRepositoryTransition(stateS12, stateS212, "I");
JpaRepositoryTransition transitionS211ToS12 = new JpaRepositoryTransition(stateS211, stateS12, "I");
JpaRepositoryTransition transitionS11 = new JpaRepositoryTransition(stateS11, stateS11, "J");
JpaRepositoryTransition transitionS2ToS1 = new JpaRepositoryTransition(stateS2, stateS1, "K");
transitionRepository.save(transitionS1ToS1);
transitionRepository.save(transitionS1ToS11);
transitionRepository.save(transitionS21ToS211);
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS1ToS0);
transitionRepository.save(transitionS211ToS21);
transitionRepository.save(transitionS0ToS211);
transitionRepository.save(transitionS1ToS211);
transitionRepository.save(transitionS2ToS21);
transitionRepository.save(transitionS11ToS211);
transitionRepository.save(transitionS0);
transitionRepository.save(transitionS1);
transitionRepository.save(transitionS2);
transitionRepository.save(transitionS11ToS12);
transitionRepository.save(transitionS12ToS212);
transitionRepository.save(transitionS211ToS12);
transitionRepository.save(transitionS11);
transitionRepository.save(transitionS2ToS1);
你可以在这里找到一个完整的示例 这里。这个示例还展示了如何从包含实体类定义的现有 JSON 文件预填充存储库。
Redis
实际用于 Redis 实例的存储库实现包括 RedisStateRepository、RedisTransitionRepository、RedisActionRepository 和 RedisGuardRepository,它们分别由实体类 RedisRepositoryState、RedisRepositoryTransition、RedisRepositoryAction 和 RedisRepositoryGuard 提供支持。
下一个示例展示了手动更新 Redis 状态和转换的通用方法。这相当于 SimpleMachine 中展示的机器。
@Autowired
StateRepository<RedisRepositoryState> stateRepository;
@Autowired
TransitionRepository<RedisRepositoryTransition> transitionRepository;
void addConfig() {
RedisRepositoryState stateS1 = new RedisRepositoryState("S1", true);
RedisRepositoryState stateS2 = new RedisRepositoryState("S2");
RedisRepositoryState stateS3 = new RedisRepositoryState("S3");
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
RedisRepositoryTransition transitionS1ToS2 = new RedisRepositoryTransition(stateS1, stateS2, "E1");
RedisRepositoryTransition transitionS2ToS3 = new RedisRepositoryTransition(stateS2, stateS3, "E2");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
}
以下示例等同于 SimpleSubMachine 中展示的机器:
@Autowired
StateRepository<RedisRepositoryState> stateRepository;
@Autowired
TransitionRepository<RedisRepositoryTransition> transitionRepository;
void addConfig() {
RedisRepositoryState stateS1 = new RedisRepositoryState("S1", true);
RedisRepositoryState stateS2 = new RedisRepositoryState("S2");
RedisRepositoryState stateS3 = new RedisRepositoryState("S3");
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
RedisRepositoryTransition transitionS1ToS2 = new RedisRepositoryTransition(stateS1, stateS2, "E1");
RedisRepositoryTransition transitionS2ToS3 = new RedisRepositoryTransition(stateS2, stateS3, "E2");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
}
MongoDB
MongoDB 实例的实际存储库实现是 MongoDbStateRepository、MongoDbTransitionRepository、MongoDbActionRepository 和 MongoDbGuardRepository,它们分别由实体类 MongoDbRepositoryState、MongoDbRepositoryTransition、MongoDbRepositoryAction 和 MongoDbRepositoryGuard 支持。
下一个示例展示了手动更新 MongoDB 状态和转换的通用方法。这相当于 SimpleMachine 中展示的机器。
@Autowired
StateRepository<MongoDbRepositoryState> stateRepository;
@Autowired
TransitionRepository<MongoDbRepositoryTransition> transitionRepository;
void addConfig() {
MongoDbRepositoryState stateS1 = new MongoDbRepositoryState("S1", true);
MongoDbRepositoryState stateS2 = new MongoDbRepositoryState("S2");
MongoDbRepositoryState stateS3 = new MongoDbRepositoryState("S3");
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
MongoDbRepositoryTransition transitionS1ToS2 = new MongoDbRepositoryTransition(stateS1, stateS2, "E1");
MongoDbRepositoryTransition transitionS2ToS3 = new MongoDbRepositoryTransition(stateS2, stateS3, "E2");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
}
以下示例与 SimpleSubMachine 中展示的机器等效。
@Autowired
StateRepository<MongoDbRepositoryState> stateRepository;
@Autowired
TransitionRepository<MongoDbRepositoryTransition> transitionRepository;
void addConfig() {
MongoDbRepositoryState stateS1 = new MongoDbRepositoryState("S1", true);
MongoDbRepositoryState stateS2 = new MongoDbRepositoryState("S2");
MongoDbRepositoryState stateS3 = new MongoDbRepositoryState("S3");
MongoDbRepositoryState stateS21 = new MongoDbRepositoryState("S21", true);
stateS21.setParentState(stateS2);
MongoDbRepositoryState stateS22 = new MongoDbRepositoryState("S22");
stateS22.setParentState(stateS2);
stateRepository.save(stateS1);
stateRepository.save(stateS2);
stateRepository.save(stateS3);
stateRepository.save(stateS21);
stateRepository.save(stateS22);
MongoDbRepositoryTransition transitionS1ToS2 = new MongoDbRepositoryTransition(stateS1, stateS2, "E1");
MongoDbRepositoryTransition transitionS2ToS3 = new MongoDbRepositoryTransition(stateS21, stateS22, "E2");
MongoDbRepositoryTransition transitionS21ToS22 = new MongoDbRepositoryTransition(stateS2, stateS3, "E3");
transitionRepository.save(transitionS1ToS2);
transitionRepository.save(transitionS2ToS3);
transitionRepository.save(transitionS21ToS22);
}
仓库持久化
除了将机器配置存储在外部仓库中(如仓库配置所示),您还可以将机器持久化到仓库中。
StateMachineRepository 接口是一个与机器持久化交互的中心访问点,并由实体类 RepositoryStateMachine 支持。
JPA
JPA 的实际存储库实现是 JpaStateMachineRepository,它由实体类 JpaRepositoryStateMachine 支持。
以下示例展示了使用 JPA 持久化机器的通用方法:
@Autowired
StateMachineRepository<JpaRepositoryStateMachine> stateMachineRepository;
void persist() {
JpaRepositoryStateMachine machine = new JpaRepositoryStateMachine();
machine.setMachineId("machine");
machine.setState("S1");
// raw byte[] representation of a context
machine.setStateMachineContext(new byte[] { 0 });
stateMachineRepository.save(machine);
}
Redis
实际的 Redis 存储库实现是 RedisStateMachineRepository,它由实体类 RedisRepositoryStateMachine 提供支持。
以下示例展示了持久化 Redis 机器的通用方法:
@Autowired
StateMachineRepository<RedisRepositoryStateMachine> stateMachineRepository;
void persist() {
RedisRepositoryStateMachine machine = new RedisRepositoryStateMachine();
machine.setMachineId("machine");
machine.setState("S1");
// raw byte[] representation of a context
machine.setStateMachineContext(new byte[] { 0 });
stateMachineRepository.save(machine);
}
MongoDB
MongoDB 的实际仓库实现是 MongoDbStateMachineRepository,它由实体类 MongoDbRepositoryStateMachine 支持。
以下示例展示了持久化 MongoDB 机器的通用方法:
@Autowired
StateMachineRepository<MongoDbRepositoryStateMachine> stateMachineRepository;
void persist() {
MongoDbRepositoryStateMachine machine = new MongoDbRepositoryStateMachine();
machine.setMachineId("machine");
machine.setState("S1");
// raw byte[] representation of a context
machine.setStateMachineContext(new byte[] { 0 });
stateMachineRepository.save(machine);
}