附录
附录 A:支持内容
本附录提供了本参考文档中使用的类和材料的通用信息。
本文档中使用的类
以下列表展示了本参考指南中使用的类:
public enum States {
SI,S1,S2,S3,S4,SF
}
public enum States2 {
S1,S2,S3,S4,S5,SF,
S2I,S21,S22,S2F,
S3I,S31,S32,S3F
}
public enum States3 {
S1,S2,SH,
S2I,S21,S22,S2F
}
public enum Events {
E1,E2,E3,E4,EF
}
附录 B:状态机概念
本附录提供了关于状态机的一般信息。
快速示例
假设我们有名为 STATE1 和 STATE2 的状态,以及名为 EVENT1 和 EVENT2 的事件,你可以按照下图所示定义状态机的逻辑:
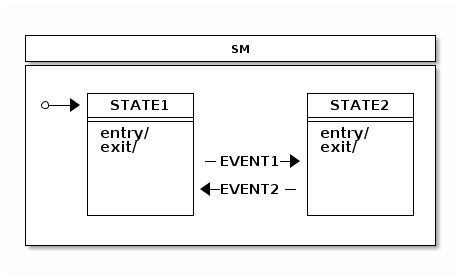
以下列表定义了前面图像中的状态机:
public enum States {
STATE1, STATE2
}
public enum Events {
EVENT1, EVENT2
}
@Configuration
@EnableStateMachine
public class Config1 extends EnumStateMachineConfigurerAdapter<States, Events> {
@Override
public void configure(StateMachineStateConfigurer<States, Events> states)
throws Exception {
states
.withStates()
.initial(States.STATE1)
.states(EnumSet.allOf(States.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<States, Events> transitions)
throws Exception {
transitions
.withExternal()
.source(States.STATE1).target(States.STATE2)
.event(Events.EVENT1)
.and()
.withExternal()
.source(States.STATE2).target(States.STATE1)
.event(Events.EVENT2);
}
}
@WithStateMachine
public class MyBean {
@OnTransition(target = "STATE1")
void toState1() {
}
@OnTransition(target = "STATE2")
void toState2() {
}
}
public class MyApp {
@Autowired
StateMachine<States, Events> stateMachine;
void doSignals() {
stateMachine
.sendEvent(Mono.just(MessageBuilder
.withPayload(Events.EVENT1).build()))
.subscribe();
stateMachine
.sendEvent(Mono.just(MessageBuilder
.withPayload(Events.EVENT2).build()))
.subscribe();
}
}
术语表
状态机
驱动状态集合的主要实体,包括区域(regions)、转换(transitions)和事件(events)。
状态
状态(state)模拟了一种在某个不变条件保持期间的情况。状态是状态机(state machine)的主要实体,其中状态的变化由事件驱动。
扩展状态
扩展状态是保存在状态机中的一组特殊变量,用于减少所需状态的数量。
过渡
转换是源状态和目标状态之间的一种关系。它可能是复合转换的一部分,复合转换将状态机从一个状态配置带到另一个状态配置,代表了状态机对特定类型事件发生的完整响应。
事件
发送到状态机并驱动各种状态变化的实体。
初始状态
状态机启动时所处的特殊状态。初始状态总是与特定的状态机或区域绑定。具有多个区域的状态机可能会有多个初始状态。
最终状态
(也称为最终状态。)一种特殊的状态,表示封闭区域已完成。如果封闭区域直接包含在状态机中,并且状态机中的所有其他区域也都已完成,则整个状态机完成。
历史状态
一种伪状态,允许状态机记住其最后的活动状态。存在两种类型的历史状态:浅层(仅记住顶层状态)和深层(记住子状态机中的活动状态)。
选择状态
一种伪状态,允许基于(例如)事件头或扩展状态变量做出转换选择。
连接状态
一种伪状态,与选择状态相对类似,但允许多个传入转换,而选择状态只允许一个传入转换。
Fork 状态
一个伪状态,用于控制进入某个区域的入口。
连接状态
一个伪状态,用于控制从区域中的退出。
入口点
一种伪状态,允许受控进入子状态机。
退出点
一种伪状态,允许从子状态机中受控退出。
区域
一个区域是复合状态或状态机的一个正交部分。它包含状态和转换。
Guard
一个布尔表达式,基于扩展状态变量和事件参数的值动态评估。守卫条件通过仅在评估为 TRUE 时启用动作或转换,并在评估为 FALSE 时禁用它们,来影响状态机的行为。
操作
动作(action)是在触发转换期间运行的行为。
状态机速成课程
本附录提供了关于状态机概念的通用速成课程。
状态
状态是状态机所处的一个模型。用现实世界的例子来描述状态总是比在通用文档中尝试使用抽象概念更容易。为此,考虑一个简单的键盘例子——我们大多数人每天都在使用键盘。如果你有一个完整的键盘,左边是普通键,右边是数字键区,你可能已经注意到数字键区可能处于两种不同的状态,这取决于 Num Lock 是否激活。如果 Num Lock 未激活,按下数字键区的键会使用箭头等进行导航。如果数字键区是激活的,按下这些键会输入数字。本质上,键盘的数字键区部分可以处于两种不同的状态。
为了将状态概念与编程联系起来,这意味着你可以依赖状态、状态变量或与状态机的其他交互,而不是使用标志位、嵌套的 if/else/break 子句或其他不切实际(有时甚至是曲折的)逻辑。
伪状态
伪状态(Pseudostate)是一种特殊类型的状态,通常通过赋予状态特殊含义(例如初始状态)来为状态机引入更高层次的逻辑。状态机可以在内部通过执行 UML 状态机概念中提供的各种操作来对这些状态做出反应。
初始
每个状态机都需要初始伪状态(Initial pseudostate),无论你有一个简单的单层状态机,还是由子状态机或区域组成的更复杂的状态机。初始状态定义了状态机启动时应进入的位置。如果没有它,状态机就是不完整的。
结束
终止伪状态(也称为“结束状态”)表示某个特定的状态机已经到达其最终状态。实际上,这意味着状态机不再处理任何事件,也不会转移到任何其他状态。然而,在子状态机作为区域的情况下,状态机可以从其终止状态重新启动。
Choice
你可以使用 Choice 伪状态 从该状态中选择一个动态条件分支的转换。动态条件由守卫(guards)评估,从而选择一个分支。通常使用简单的 if/elseif/else 结构来确保选择一个分支。否则,状态机可能会陷入死锁,配置也会变得不合法。
连接点
Junction 伪状态在功能上与选择(choice)类似,两者都通过 if/elseif/else 结构实现。唯一的真正区别在于,junction 允许多个进入的转换,而 choice 只允许一个。这种区别在很大程度上是学术性的,但在某些情况下确实存在差异,例如当状态机设计用于真实的 UI 建模框架时。
历史
你可以使用 History 伪状态 来记住最后一个活动的状态配置。在状态机退出后,你可以使用历史状态来恢复之前已知的配置。有两种类型的历史状态可用:SHALLOW(仅记住状态机本身的活动状态)和 DEEP(还会记住嵌套状态)。
历史状态可以通过监听状态机事件在外部实现,但这很快就会使逻辑变得非常复杂,尤其是当状态机包含复杂的嵌套结构时。让状态机本身处理历史状态的记录会使事情变得简单得多。用户只需创建一个到历史状态的转换,状态机就会处理所需的逻辑以返回到其最后已知的记录状态。
在状态机中,如果 Transition 终止于一个历史状态,而该状态之前未被进入过(即没有历史记录)或者已经到达其结束状态,则可以通过使用默认历史机制强制状态机进入特定的子状态。这种转换从历史状态开始,并终止于包含历史状态的区域的特定顶点(默认历史状态)。只有在执行该转换会导致进入历史状态且该状态之前从未被激活过时,才会执行此转换。否则,将执行正常的进入区域的历史记录。如果未定义默认历史转换,则执行区域的标准默认进入操作。
Fork
你可以使用 Fork 伪状态 来显式进入一个或多个区域。下图展示了 fork 的工作原理:
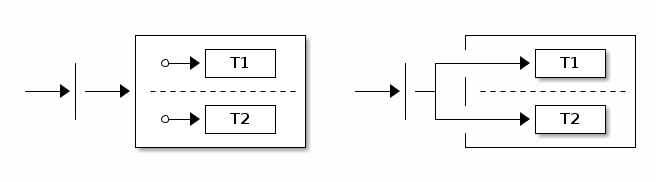
目标状态可以是一个包含区域(regions)的父状态,这意味着通过进入其初始状态来激活区域。你也可以直接将目标添加到区域中的任何状态,这样可以更受控制地进入某个状态。
连接
Join 伪状态 将来自不同区域的多个转换合并在一起。它通常用于等待并阻塞参与的区域,直到它们到达其合并目标状态。下图展示了 join 的工作原理:
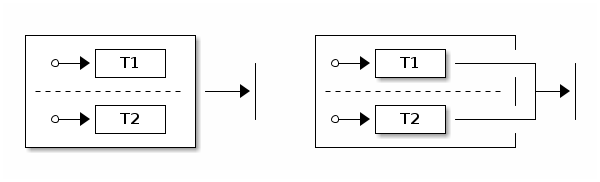
源状态可以是一个包含区域(regions)的父状态,这意味着连接状态(join states)是参与区域的最终状态。你也可以将源状态定义为区域中的任何状态,这样可以从区域中实现可控退出。
入口点
入口点伪状态(Entry Point pseudostate)表示状态机或组合状态的入口点,它提供了对状态或状态机内部的封装。在拥有该入口点的状态机或组合状态的每个区域中,最多只有一条从入口点到该区域内某个顶点的转换。
退出点
退出点伪状态 是状态机或复合状态的退出点,它提供了对状态或状态机内部内容的封装。在复合状态(或由子机状态引用的状态机)的任何区域内终止于退出点的转换意味着退出该复合状态或子机状态(并执行其关联的退出行为)。
守卫条件
守卫条件(Guard conditions)是基于扩展状态变量和事件参数评估为 TRUE 或 FALSE 的表达式。守卫与动作和转换一起使用,以动态选择是否应运行特定动作或转换。守卫、事件参数和扩展状态变量的各个方面旨在使状态机设计更加简单。
事件
事件(Event)是驱动状态机最常用的触发行为。在状态机中,还有其他方式可以触发行为(例如定时器),但事件是真正让用户与状态机交互的方式。事件也被称为“信号”(Signals)。它们基本上表示可能改变状态机状态的某种情况。
过渡
一个过渡(transition)是源状态(source state)和目标状态(target state)之间的关系。从一个状态切换到另一个状态是由触发器(trigger)引起的状态转换(state transition)。
内部转换
内部转换(Internal transition)用于在不需要引起状态转换的情况下执行某些操作。在内部转换中,源状态和目标状态始终相同,并且在没有状态进入和退出操作的情况下,它与自转换(self-transition)是相同的。
外部与本地过渡
在大多数情况下,外部转换和本地转换在功能上是等效的,除非转换发生在超状态和子状态之间。如果目标状态是源状态的子状态,本地转换不会导致源状态的退出和进入。相反,如果目标是源状态的超状态,本地转换不会导致目标状态的退出和进入。下图展示了具有非常简单超状态和子状态的本地转换和外部转换之间的区别:
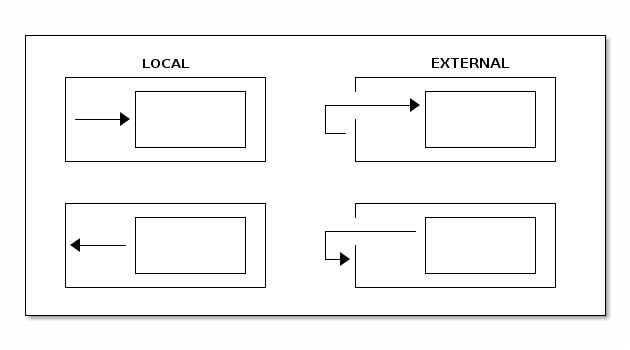
触发器
触发器开始一个转换。触发器可以由事件或计时器驱动。
操作
Actions 真正地将状态机的状态变化与用户的代码绑定在一起。状态机可以在各种变化以及状态机的步骤(例如进入或退出状态)或执行状态转换时运行一个动作。
动作通常可以访问状态上下文,这使得运行的代码能够以多种方式与状态机进行交互。状态上下文暴露了整个状态机,因此用户可以访问扩展的状态变量、事件头(如果转换基于事件),或实际的转换(在这里可以更详细地了解状态变化的来源和去向)。
层次状态机
层次状态机(hierarchical state machine)的概念用于简化状态设计,当某些特定状态必须共存时。
层次状态是 UML 状态机相对于传统状态机(如 Mealy 或 Moore 机)的一项真正创新。层次状态允许你定义某种抽象级别(类似于 Java 开发人员可能使用抽象类定义类结构的方式)。例如,通过嵌套状态机,你可以在多个状态级别上定义转换(可能带有不同的条件)。状态机总是尝试查看当前状态是否能够处理事件,同时结合转换守卫条件。如果这些条件未评估为 TRUE,状态机则会查看父状态能够处理什么。
区域
区域(也称为正交区域)通常被视为应用于状态的互斥或(XOR)操作。在状态机的术语中,区域的概念通常有点难以理解,但通过一个简单的例子,事情会变得稍微简单一些。
我们中的一些人拥有一个全尺寸键盘,左侧是主键,右侧是数字键。你可能已经注意到,两侧实际上都有自己的状态,当你按下“numlock”键时(它只改变数字小键盘本身的行为),你就会看到这一点。如果你没有全尺寸键盘,你可以购买一个外置的 USB 数字小键盘。鉴于键盘的左侧和右侧可以各自独立存在,它们必须具有完全不同的状态,这意味着它们在不同的状态机上运行。用状态机的术语来说,键盘的主要部分是一个区域,而数字小键盘是另一个区域。
将两个不同的状态机作为完全独立的实体来处理会有些不便,因为它们在某些方面仍然以某种方式协同工作。这种独立性允许正交区域在状态机中的单个状态内以多个同时存在的状态组合在一起。
附录 C: 分布式状态机技术文档
本附录提供了关于在 Spring Statemachine 中使用 Zookeeper 实例的更详细的技术文档。
摘要
在单个 JVM 上运行的单个状态机实例之上引入“分布式状态”是一个困难且复杂的话题。“分布式状态机”的概念在简单状态机的基础上引入了一些相对复杂的问题,这主要是由于其运行至完成的模型,以及更广泛地说,由于其单线程执行模型,尽管正交区域可以并行运行。另一个自然的问题是,状态机转换的执行是由触发器驱动的,这些触发器要么基于 event,要么基于 timer。
Spring State Machine 试图通过支持分布式状态机来解决跨越 JVM 边界实现通用“状态机”的问题。在这里,我们展示了如何在多个 JVM 和 Spring 应用上下文中使用通用的“状态机”概念。
我们发现,如果精心选择 Distributed State Machine 抽象,并且支持分布式状态存储库保证 CP 就绪性,那么就可以创建一个一致的状态机,该状态机可以在集群中与其他状态机共享分布式状态。
我们的结果表明,如果底层存储库是“CP”(稍后讨论状态机技术论文介绍),那么分布式状态变化是一致的。我们预期,我们的分布式状态机可以为需要处理共享分布式状态的应用程序提供基础。该模型旨在为云应用程序提供良好的方法,使它们能够以更简单的方式进行通信,而无需显式构建这些分布式状态概念。
引言
Spring State Machine 并不强制使用单线程执行模型,因为一旦使用了多个区域(regions),在应用了必要的配置后,这些区域可以并行执行。这是一个重要的话题,因为一旦用户希望实现并行状态机执行,它将使得独立区域的状态变更更快。
当状态变化不再由本地 JVM 或本地状态机实例中的触发器驱动时,转换逻辑需要在外部通过任意持久化存储进行控制。该存储需要有一种方式,在分布式状态发生变化时通知参与的状态机。
CAP 定理 指出,分布式计算机系统不可能同时提供以下三个保证:一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。
这意味着,无论选择哪种持久化存储作为后端,建议采用“CP”模式。在此上下文中,“CP”代表“一致性”(consistency)和“分区容忍性”(partition tolerance)。自然地,分布式的 Spring Statemachine 并不关心其“CAP”级别,但在实际情况中,“一致性”和“分区容忍性”比“可用性”(availability)更为重要。这也是为什么(例如)Zookeeper 使用“CP”存储的确切原因。
本文中展示的所有测试都是通过在以下环境中运行自定义的 Jepsen 测试来完成的:
-
一个集群包含节点 n1、n2、n3、n4 和 n5。
-
每个节点都有一个
Zookeeper实例,该实例与其他所有节点一起构成一个 ensemble。 -
每个节点都安装了一个 Web 示例,用于连接到本地的
Zookeeper节点。 -
每个状态机实例仅与本地的
Zookeeper实例通信。虽然可以将机器连接到多个实例,但这里没有使用这种方式。 -
所有状态机实例在启动时,都会通过使用 Zookeeper ensemble 创建一个
StateMachineEnsemble。 -
每个示例都包含一个自定义的 REST API,Jepsen 使用它来发送事件并检查特定状态机的状态。
所有针对 Spring Distributed Statemachine 的 Jepsen 测试都可以从 Jepsen Tests 获取。
通用概念
Distributed State Machine 的一个设计决策是不让每个单独的状态机实例意识到它是“分布式集合”的一部分。由于 StateMachine 的主要功能和特性可以通过其接口访问,因此将这个实例包装在一个 DistributedStateMachine 中是有意义的,该 DistributedStateMachine 会拦截所有状态机通信,并与一个集合协作以协调分布式状态变更。
另一个重要概念是能够从状态机中持久化足够的信息,以便将状态机的状态从任意状态重置为新的反序列化状态。当一个新的状态机实例加入到一个集合中,并需要将其内部状态与分布式状态同步时,这自然是必需的。通过结合使用分布式状态和状态持久化的概念,可以创建一个分布式状态机。目前,Distributed State Machine 的唯一支持存储库是通过使用 Zookeeper 实现的。
如使用分布式状态中所述,通过将 StateMachine 的实例包装在 DistributedStateMachine 中来启用分布式状态。具体的 StateMachineEnsemble 实现是 ZookeeperStateMachineEnsemble,它提供了与 Zookeeper 的集成。
ZookeeperStateMachinePersist 的作用
我们希望有一个通用的接口(StateMachinePersist),可以将 StateMachineContext 持久化到任意存储中,而 ZookeeperStateMachinePersist 则为 Zookeeper 实现了这个接口。
ZookeeperStateMachineEnsemble 的作用
当分布式状态机使用一组序列化的上下文来更新其自身状态时,使用 Zookeeper 时,我们面临一个概念性问题,即如何监听这些上下文的变化。我们可以将上下文序列化到 Zookeeper 的 znode 中,并最终在 znode 数据被修改时进行监听。然而,Zookeeper 并不保证你会收到每次数据变化的通知,因为一旦注册的 watcher 触发,它就会被禁用,用户需要重新注册该 watcher。在这短暂的时间内,znode 的数据可能会被更改,从而导致事件丢失。实际上,在并发环境中通过多个线程更改数据时,很容易错过这些事件。
为了解决这个问题,我们将单个上下文更改保存在多个 znode 中,并使用一个简单的整数计数器来标记哪个 znode 是当前活跃的。这样做可以让我们重放错过的事件。我们不希望创建越来越多的 znode,然后再删除旧的 znode。相反,我们使用了一个简单的循环 znode 集合的概念。这使得我们可以使用一组预定义的 znode,其中当前节点可以通过一个简单的整数计数器来确定。我们通过跟踪主 znode 的数据版本(在 Zookeeper 中,这是一个整数)已经拥有了这个计数器。
为了避免整数溢出时出现问题,循环缓冲区的大小被规定为 2 的幂。因此,我们无需处理任何特殊情况。
分布式容错
为了展示各种分布式操作如何在实际中影响状态机,我们使用一组 Jepsen 测试来模拟可能发生在真实分布式集群中的各种情况。这些情况包括网络层面的“脑裂”、多个“分布式状态机”的并行事件,以及“扩展状态变量”的变化。Jepsen 测试基于一个示例 Web,该示例实例在多个主机上运行,每个运行状态机的节点上都有一个 Zookeeper 实例。本质上,每个状态机示例都连接到一个本地的 Zookeeper 实例,这使得我们能够通过 Jepsen 来模拟网络条件。
本章后面展示的图表包含了直接映射到状态图的状态和事件,你可以在 Web 中找到相关内容。
孤立事件
将孤立的事件发送到集合中的单个状态机是最简单的测试场景,它展示了单个状态机中的状态变化能够正确地传播到集合中的其他状态机。
在这个测试中,我们演示了一台机器中的状态变化最终会导致其他机器中的一致状态变化。下图展示了一个测试状态机的事件和状态变化:
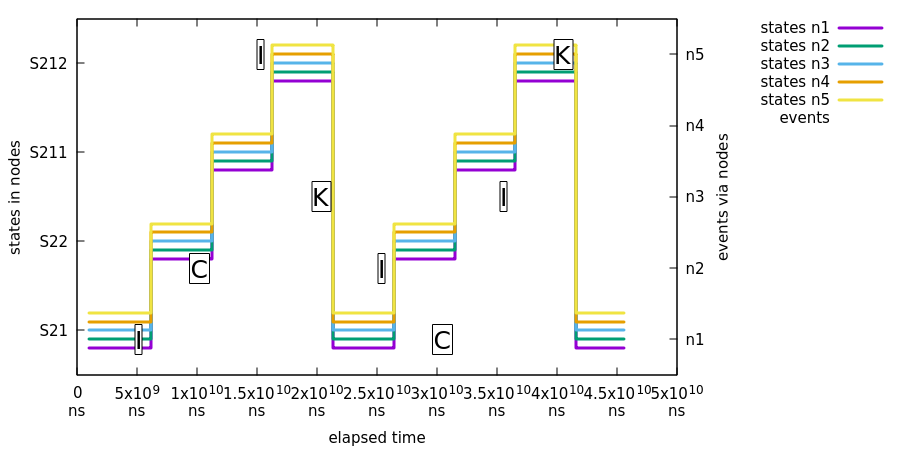
在前面的图片中:
-
所有机器报告状态为
S21。 -
事件
I被发送到节点n1,所有节点报告状态从S21变为S22。 -
事件
C被发送到节点n2,所有节点报告状态从S22变为S211。 -
事件
I被发送到节点n5,所有节点报告状态从S211变为S212。 -
事件
K被发送到节点n3,所有节点报告状态从S212变为S21。 -
我们再次通过随机节点循环发送事件
I、C、I和K。
并行事件
多个分布式状态机的一个逻辑问题是,如果同一事件同时发送到多个状态机,只有一个事件会导致分布式状态转换。这是一个预料之中的情况,因为第一个能够改变分布式状态的状态机(对于该事件)控制了分布式转换逻辑。实际上,所有接收到相同事件的其他状态机会默默地丢弃该事件,因为分布式状态不再处于可以处理特定事件的状态。
在以下图像所示的测试中,我们展示了由并行事件引起的状态变化最终会导致整个集合中所有机器的一致状态变化:
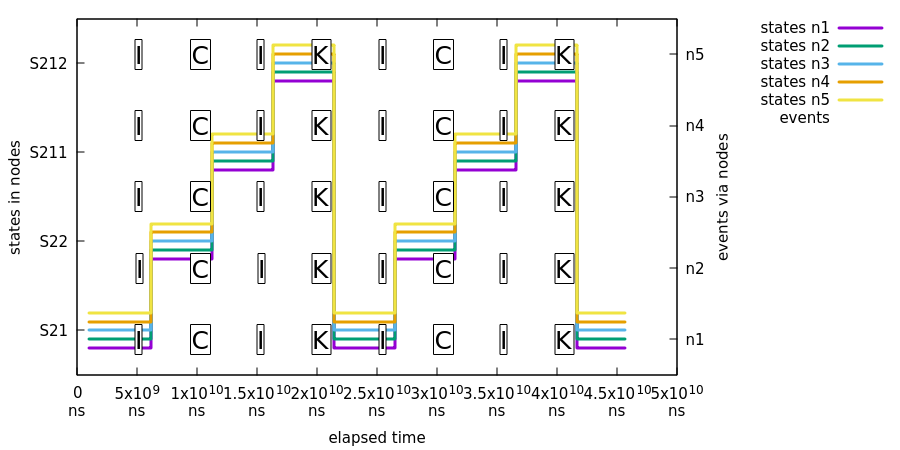
在前面的图中,我们使用了与之前的示例(孤立事件)相同的事件流,不同之处在于事件总是发送到所有节点。
并发扩展状态变量变更
扩展状态机变量在任何给定时间都不能保证是原子的,但在分布式状态变更之后,ensemble 中的所有状态机都应该具有同步的扩展状态。
在这个测试中,我们演示了一个分布式状态机中扩展状态变量的变化最终会在所有分布式状态机中达到一致。下图展示了这个测试:
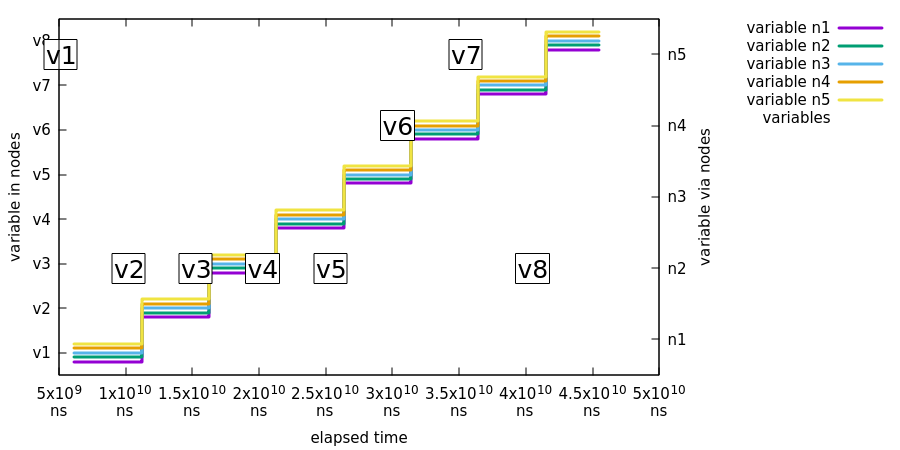
在前面的图片中:
-
事件
J被发送到节点n5,事件变量testVariable的值为v1。然后所有节点都报告拥有一个名为testVariable的变量,其值为v1。 -
事件
J从变量v2到v8重复执行,进行相同的检查。
分区容错性
我们需要始终假设,集群中的事物迟早会出问题,无论是 Zookeeper 实例崩溃、状态机崩溃,还是诸如“脑裂”之类的网络问题。(脑裂是指现有集群成员被隔离,导致只有部分主机能够相互看到的情况)。通常的情况是,脑裂会创建一个 ensemble 的少数派和多数派分区,使得少数派中的主机在网络状态恢复之前无法参与 ensemble。
在以下测试中,我们证明了在 ensemble 中各种类型的脑裂最终会导致所有分布式状态机的完全同步状态。
在网络中,有两种场景会导致直接的脑裂问题,其中 Zookeeper 和 Statemachine 实例被分成两半(假设每个 Statemachine 都连接到一个本地的 Zookeeper 实例):
-
如果当前的 Zookeeper 领导者保留在多数派中,所有连接到多数派的客户端将继续正常运行。
-
如果当前的 Zookeeper 领导者被留在少数派中,所有客户端将断开与它的连接,并尝试重新连接,直到之前的少数派成员成功重新加入现有的多数派集群。
在我们当前的 Jepsen 测试中,无法区分 Zookeeper 脑裂场景中领导者是在多数派还是少数派,因此我们需要多次运行测试来实现这种情况。
在以下图表中,我们已经将状态机的错误状态映射为 error,以表示状态机处于错误状态而不是正常状态。在解释图表状态时,请记住这一点。
在第一个测试中,我们展示了当现有的 Zookeeper leader 保持在多数时,五台机器中的三台会继续正常运行。下图展示了这个测试:
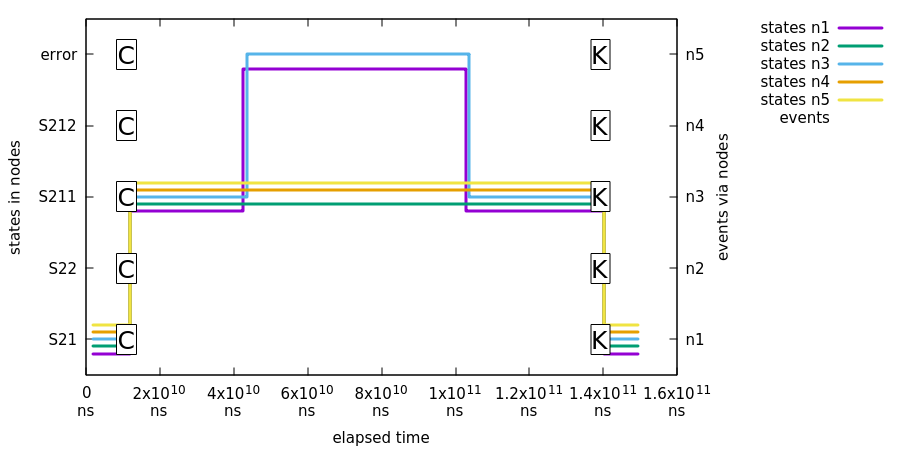
在前面的图片中:
-
第一个事件
C被发送到所有机器,导致状态变为S211。 -
Jepsen 干扰器引发了脑裂,导致
n1/n2/n5和n3/n4之间的分区。节点n3/n4处于少数派,而节点n1/n2/n5构成了一个新的健康多数派。多数派中的节点继续正常运行,但少数派中的节点进入错误状态。 -
Jepsen 恢复了网络,一段时间后,节点
n3/n4重新加入集群并同步其分布式状态。 -
最后,事件
K1被发送到所有状态机,以确保集群正常工作。此状态变化使状态回到S21。
在第二个测试中,我们展示了当现有的 zookeeper leader 被保持在少数派时,所有机器都会出错。下图展示了第二个测试:
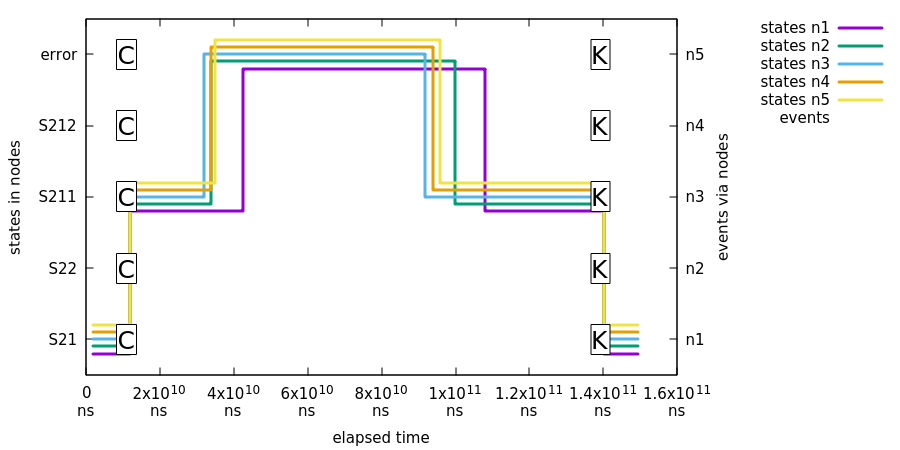
在前面的图像中:
-
第一个事件
C被发送到所有机器,导致状态变为S211。 -
Jepsen 的 nemesis 导致脑裂,进而导致分区,使得现有的
Zookeeper领导者被保留在少数派中,所有实例都与集群断开连接。 -
Jepsen 修复了网络,经过一段时间后,所有节点重新加入集群并同步其分布式状态。
-
最后,事件
K1被发送到所有状态机,以确保集群正常工作。此状态变化将状态恢复为S21。
崩溃和加入容错
在此测试中,我们演示了终止一个现有的状态机,然后将一个新实例重新加入集群后,分布式状态保持健康,并且新加入的状态机能够正确同步其状态。下图展示了崩溃和加入容错测试:
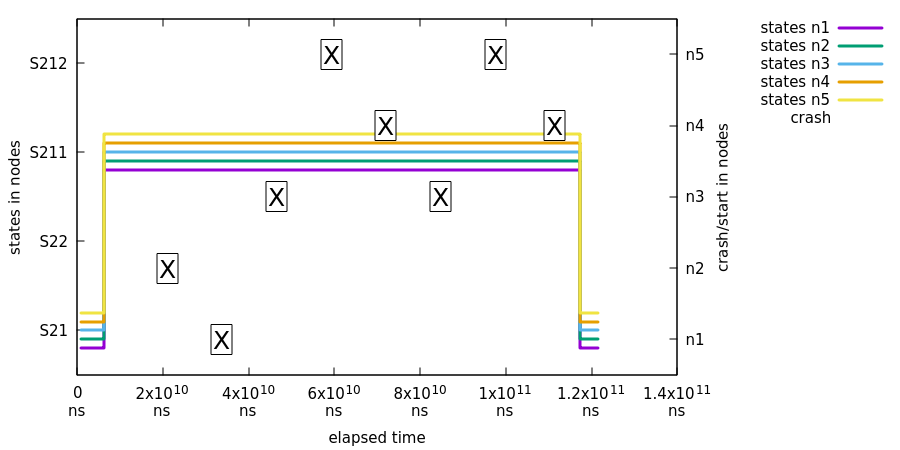
在此测试中,第一个 X 和最后一个 X 之间的状态未被检查。因此,图中在这之间显示了一条平坦的线。状态仅在 S21 和 S211 之间的状态变化发生时被检查。
在前面的图片中:
-
所有的状态机都从初始状态(
S21)转换到状态S211,以便我们可以在加入时测试正确的状态同步。 -
X标记表示特定节点已经崩溃并重新启动。 -
同时,我们从所有机器请求状态并绘制结果。
-
最后,我们简单地执行从
S211回到S21的转换,以确保所有状态机仍然正常运行。
开发者文档
本附录为希望贡献的开发者或希望了解状态机工作原理或理解其内部概念的其他人员提供通用信息。
状态机配置模型
StateMachineModel 和其他相关的 SPI 类是在各种配置和工厂类之间的抽象层。这也使得其他人更容易集成并构建状态机。
如下列表所示,您可以通过使用配置数据类构建模型来实例化状态机,然后让工厂构建状态机:
// setup configuration data
ConfigurationData<String, String> configurationData = new ConfigurationData<>();
// setup states data
Collection<StateData<String, String>> stateData = new ArrayList<>();
stateData.add(new StateData<String, String>("S1", true));
stateData.add(new StateData<String, String>("S2"));
StatesData<String, String> statesData = new StatesData<>(stateData);
// setup transitions data
Collection<TransitionData<String, String>> transitionData = new ArrayList<>();
transitionData.add(new TransitionData<String, String>("S1", "S2", "E1"));
TransitionsData<String, String> transitionsData = new TransitionsData<>(transitionData);
// setup model
StateMachineModel<String, String> stateMachineModel = new DefaultStateMachineModel<>(configurationData, statesData,
transitionsData);
// instantiate machine via factory
ObjectStateMachineFactory<String, String> factory = new ObjectStateMachineFactory<>(stateMachineModel);
StateMachine<String, String> stateMachine = factory.getStateMachine();
附录 D:Reactor 迁移指南
3.x 版本的主要任务是在内部和外部尽可能多地将命令式代码迁移并转变为响应式代码。这意味着一些主要接口新增了响应式方法,并且大部分内部执行逻辑(在适用的情况下)已经迁移到由 Reactor 来处理。本质上,这意味着线程处理模型与 2.x 相比有了显著的不同。接下来的章节将详细讨论这些变化。
与机器通信
我们为 StateMachine 添加了新的响应式方法,同时保留了旧的阻塞事件方法。
Flux<StateMachineEventResult<S, E>> sendEvent(Mono<Message<E>> event);
Flux<StateMachineEventResult<S, E>> sendEvents(Flux<Message<E>> events);
Mono<List<StateMachineEventResult<S, E>>> sendEventCollect(Mono<Message<E>> event);
我们现在仅专注于使用 Spring 的 Message 和 Reactor 的 Mono 和 Flux 类。你可以发送一个 Message 的 Mono,并接收一个 StateMachineEventResult 的 Flux。请记住,在你订阅这个 Flux 之前,什么都不会发生。关于这个返回值的更多信息,请参阅 StateMachineEventResult。方法 sendEventCollect 只是一个语法糖,用于传入一个 Mono 并获取一个将结果包装为列表的 Mono。
Message<String> message = MessageBuilder.withPayload("EVENT").build();
machine.sendEvent(Mono.just(message)).subscribe();
你也可以发送一个 Flux 的消息流,而不是单一的 Mono 消息。
machine.sendEvents(Flux.just(message)).subscribe();
所有的 reactor 方法都可以供你使用,例如,为了不阻塞并在事件处理完成时执行某些操作,你可以这样做。
Mono<Message<String>> mono = Mono.just(MessageBuilder.withPayload("EVENT").build());
machine.sendEvent(mono)
.doOnComplete(() -> {
System.out.println("Event handling complete");
})
.subscribe();
返回 boolean 类型表示接受状态的旧 API 方法仍然存在,但已被弃用,并将在未来的版本中移除。
boolean accepted = machine.sendEvent("EVENT");
TaskExecutor 和 TaskScheduler
使用 TaskExecutor 进行 StateMachine 执行以及使用 TaskScheduler 进行状态操作调度的方式已经完全被 Reactor 的执行和调度所取代。
本质上,在主线程之外的执行需要在两个地方进行:首先是需要可取消的 State Actions,其次是应该始终独立执行的 Regions。目前,我们选择仅为这些操作使用 Reactor 的 Schedulers.parallel(),这应该会带来相对较好的结果,因为它会尝试自动使用系统中可用的 CPU 核心数量。
响应式示例
虽然大多数示例仍然相同,但我们已对一些示例进行了全面修改,并创建了一些新的示例:
- Tunrstile Reactive Turnstile Reactive