分块导向处理
Spring Batch 在其最常见的实现中采用了“面向块”的处理方式。面向块的处理方式指的是每次读取一条数据,并在事务边界内创建“块”进行写出。当读取的项目数量达到提交间隔时,整个块会通过 ItemWriter 写出,随后事务被提交。下图展示了这一过程:
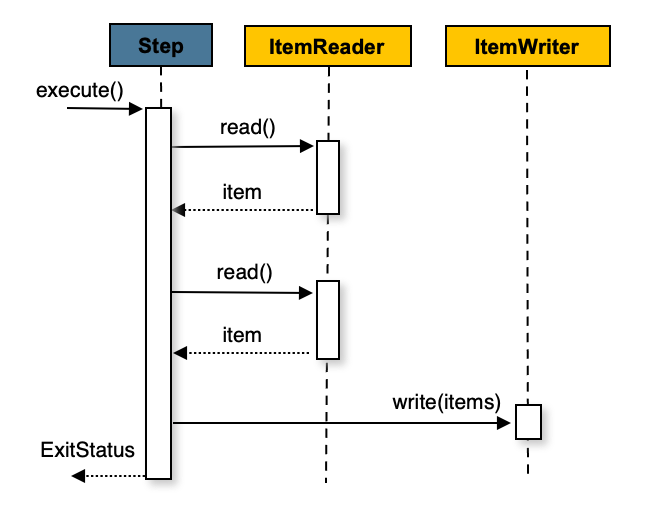
图 1. 面向分块的处理
以下伪代码以简化形式展示了相同的概念:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
itemWriter.write(items);
你也可以配置一个面向块的步骤,并可选地使用 ItemProcessor 在将项目传递给 ItemWriter 之前进行处理。下图展示了在步骤中注册 ItemProcessor 时的处理流程:

图 2. 使用项目处理器的面向块处理
以下伪代码以简化形式展示了其实现方式:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read();
if (item != null) {
items.add(item);
}
}
List processedItems = new Arraylist();
for(Object item: items){
Object processedItem = itemProcessor.process(item);
if (processedItem != null) {
processedItems.add(processedItem);
}
}
itemWriter.write(processedItems);
有关项目处理器及其使用案例的更多详情,请参阅项目处理部分。
章节总结
📄️ 配置步骤
尽管一个步骤所需的依赖项列表相对较短,但它是一个极其复杂的类,可能包含许多协作组件。
📄️ 从父步骤继承
如果一组步骤共享相似的配置,那么定义一个“父”步骤可能很有帮助,具体步骤可以从父步骤继承属性。类似于 Java 中的类继承,“子”步骤会将其元素和属性与父步骤的元素和属性合并。子步骤还会覆盖父步骤的任何步骤。
📄️ 提交间隔
如前所述,一个步骤会读取并写入数据项,并定期使用提供的 PlatformTransactionManager 进行提交。当提交间隔设置为 1 时,它会在写入每个单独的数据项后提交。这在许多情况下并不理想,因为开始和提交事务的成本很高。理想情况下,最好在每个事务中处理尽可能多的数据项,这完全取决于所处理的数据类型以及步骤与之交互的资源。因此,您可以配置在每次提交中处理的数据项数量。
📄️ 配置重启步骤
在“配置和运行作业”部分,我们讨论了如何重启作业。重启对步骤有诸多影响,因此可能需要一些特定的配置。
📄️ 配置跳过逻辑
在许多场景中,处理过程中遇到的错误不应导致步骤失败,而应跳过。这通常需要由理解数据本身及其含义的人员来决定。例如,财务数据可能不可跳过,因为它涉及资金转移,需要完全准确。另一方面,加载供应商列表可能允许跳过。如果某个供应商因格式错误或缺少必要信息而未能加载,可能不会造成问题。通常,这些不良记录也会被记录下来,这将在后续讨论监听器时涉及。
📄️ 配置重试逻辑
在大多数情况下,您希望异常导致跳过或步骤失败。然而,并非所有异常都是确定性的。如果在读取时遇到 FlatFileParseException,该异常总是会针对该记录抛出。重置 ItemReader 也无济于事。但对于其他异常(例如 DeadlockLoserDataAccessException,它表示当前进程试图更新另一个进程持有锁的记录),等待并重试可能会成功。
📄️ 交易属性
您可以使用事务属性来控制隔离、传播和超时设置。有关设置事务属性的更多信息,请参阅 Spring 核心文档。
📄️ 在步骤中注册 ItemStream
步骤必须在其生命周期的必要节点处理 ItemStream 回调(有关 ItemStream 接口的详细信息,请参阅 ItemStream)。当步骤执行失败并可能需要重启时,这一点至关重要,因为 ItemStream 接口是步骤获取跨执行过程所需持久化状态信息的唯一途径。
📄️ 拦截步骤执行
与 Job 类似,在 Step 的执行过程中也存在许多事件,用户可能需要在这些事件中执行某些功能。例如,当需要写入包含页脚的平面文件时,ItemWriter 需要在 Step 完成时收到通知,以便写入页脚。这可以通过多种 Step 作用域的监听器来实现。