元数据模式
概述
Spring Batch 元数据表与 Java 中表示它们的领域对象紧密对应。例如,JobInstance、JobExecution、JobParameters 和 StepExecution 分别映射到 BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、BATCH_JOB_EXECUTION_PARAMS 和 BATCH_STEP_EXECUTION。ExecutionContext 则映射到 BATCH_JOB_EXECUTION_CONTEXT 和 BATCH_STEP_EXECUTION_CONTEXT。JobRepository 负责将每个 Java 对象保存并存储到正确的表中。本附录将详细描述这些元数据表,并阐述创建它们时的诸多设计决策。在查看本附录后续描述的各种建表语句时,请注意所使用的数据类型尽可能通用。Spring Batch 提供了多种示例架构,由于不同数据库供应商处理数据类型的方式存在差异,这些架构的数据类型各不相同。下图展示了所有六个表的 ERD 模型及其相互关系:
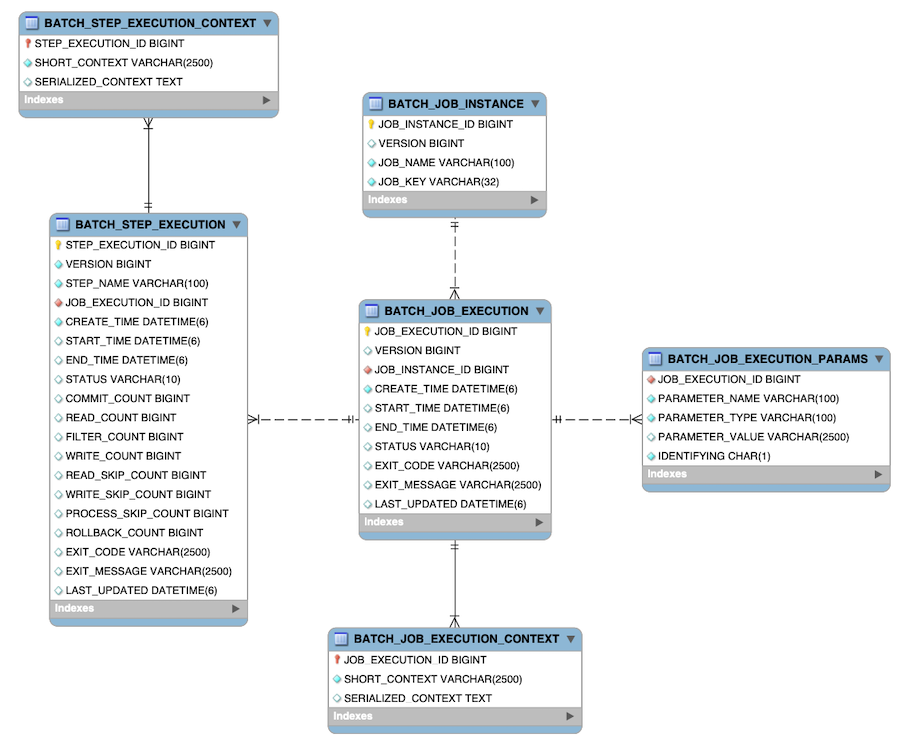
图 1. Spring Batch 元数据 ERD
示例 DDL 脚本
Spring Batch Core JAR 文件中包含了为多种数据库平台创建关系表的示例脚本(这些脚本会被作业存储库工厂 bean 或等效命名空间自动检测)。这些脚本可以直接使用,也可以根据需要修改以添加额外的索引和约束。文件名格式为 schema-*.sql,其中 * 是目标数据库平台的简称。这些脚本位于 org.springframework.batch.core 包中。
迁移 DDL 脚本
Spring Batch 提供了升级版本时需要执行的迁移 DDL 脚本。这些脚本可以在 Core Jar 文件的 org/springframework/batch/core/migration 目录下找到。迁移脚本按引入它们的版本号组织在对应的文件夹中:
-
2.2:包含从2.2之前的版本迁移到2.2版本所需的脚本 -
4.1:包含从4.1之前的版本迁移到4.1版本所需的脚本
版本
本附录中讨论的许多数据库表都包含一个版本列。该列非常重要,因为 Spring Batch 在处理数据库更新时采用了乐观锁定策略。这意味着每次记录被“触及”(更新)时,版本列中的值都会增加一。当存储库返回保存该值时,如果版本号已更改,则会抛出 OptimisticLockingFailureException,表明并发访问出现了错误。此检查是必要的,因为即使不同的批处理作业可能在不同的机器上运行,它们都使用相同的数据库表。
身份
BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION 和 BATCH_STEP_EXECUTION 每个表都包含以 _ID 结尾的列。这些字段作为各自表的主键。然而,它们并非数据库生成的键,而是由独立的序列生成的。这是必要的,因为在将某个领域对象插入数据库后,需要将分配给它的键设置在实际对象上,以便在 Java 中能够唯一标识它们。较新的数据库驱动程序(JDBC 3.0 及以上版本)支持通过数据库生成键来实现此功能。然而,为了避免依赖该特性,这里使用了序列。每种模式变体都包含以下形式的语句:
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_INSTANCE_SEQ;
许多数据库供应商不支持序列。在这些情况下,会使用变通方法,例如以下针对 MySQL 的语句:
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_INSTANCE_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_INSTANCE_SEQ values(0);
在前述案例中,每个序列都使用一个表来替代。Spring核心类MySQLMaxValueIncrementer随后会递增该表中的列,从而提供类似的功能。
BATCH_JOB_INSTANCE 表
BATCH_JOB_INSTANCE 表存储与 JobInstance 相关的所有信息,并作为整体层次结构的顶层。以下通用 DDL 语句用于创建该表:
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(32) NOT NULL
);
下表描述了每一列的含义:
-
JOB_INSTANCE_ID: 标识实例的唯一ID,同时也是主键。该列的值应可通过调用JobInstance的getId方法获取。 -
VERSION: 参见版本。 -
JOB_NAME: 从Job对象获取的作业名称。由于需要用它来标识实例,因此该值不能为空。 -
JOB_KEY:JobParameters的序列化形式,用于唯一区分同一作业的不同实例(具有相同作业名称的JobInstances必须具有不同的JobParameters,因此JOB_KEY值也不同)。
BATCH_JOB_EXECUTION_PARAMS 表
BATCH_JOB_EXECUTION_PARAMS 表存储与 JobParameters 对象相关的所有信息。它包含传递给 Job 的 0 个或多个键/值对,并作为作业运行时所用参数的记录。对于构成作业标识生成的每个参数,IDENTIFYING 标志被设置为 true。请注意,该表已进行反规范化处理。没有为每种类型创建单独的表,而是使用一个表,其中包含一个指示类型的列,如下面的列表所示:
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
PARAMETER_NAME VARCHAR(100) NOT NULL ,
PARAMETER_TYPE VARCHAR(100) NOT NULL ,
PARAMETER_VALUE VARCHAR(2500) ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
以下列表描述了每一列:
-
JOB_EXECUTION_ID: 来自BATCH_JOB_EXECUTION表的外键,指示该参数条目所属的作业执行。请注意,每次执行可能存在多行(即键/值对)。 -
PARAMETER_NAME: 参数名称。 -
PARAMETER_TYPE: 参数类型的完全限定名。 -
PARAMETER_VALUE: 参数值。 -
IDENTIFYING: 标志,指示该参数是否对相关JobInstance的身份标识有贡献。
请注意,此表没有主键。这是因为框架本身不需要主键,因此不要求设置。如有需要,您可以添加一个数据库生成的主键,这不会对框架本身造成任何问题。
BATCH_JOB_EXECUTION 表
BATCH_JOB_EXECUTION 表存储了与 JobExecution 对象相关的所有信息。每次运行一个 Job 时,总会有一个新的 JobExecution 以及此表中的一条新记录。以下清单展示了 BATCH_JOB_EXECUTION 表的定义:
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
以下列表描述了每一列:
-
JOB_EXECUTION_ID: 主键,唯一标识此执行。该列的值可通过调用JobExecution对象的getId方法获得。 -
VERSION: 参见 版本。 -
JOB_INSTANCE_ID: 来自BATCH_JOB_INSTANCE表的外键。它指示此执行所属的实例。每个实例可能有多次执行。 -
CREATE_TIME: 时间戳,表示执行被创建的时间。 -
START_TIME: 时间戳,表示执行开始的时间。 -
END_TIME: 时间戳,表示执行完成的时间,无论成功或失败。当作业当前未运行时,此列中的空值表示发生了某种类型的错误,框架在失败前无法执行最后一次保存。 -
STATUS: 字符串,表示执行的状态。可能是COMPLETED、STARTED等。此列的对象表示是BatchStatus枚举。 -
EXIT_CODE: 字符串,表示执行的退出码。对于命令行作业,这可能会被转换为数字。 -
EXIT_MESSAGE: 字符串,表示关于作业如何退出的更详细描述。在失败的情况下,这可能包含尽可能多的堆栈跟踪信息。 -
LAST_UPDATED: 时间戳,表示此执行最后一次被持久化的时间。
BATCH_STEP_EXECUTION 表
BATCH_STEP_EXECUTION 表存储了与 StepExecution 对象相关的所有信息。该表在许多方面与 BATCH_JOB_EXECUTION 表相似,并且每个创建的 JobExecution 对应每个 Step 至少会有一条记录。以下清单展示了 BATCH_STEP_EXECUTION 表的定义:
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下列表描述了每一列:
-
STEP_EXECUTION_ID: 主键,用于唯一标识此执行。该列的值应可通过调用StepExecution对象的getId方法获取。 -
VERSION: 参见 版本。 -
STEP_NAME: 此执行所属步骤的名称。 -
JOB_EXECUTION_ID: 来自BATCH_JOB_EXECUTION表的外键。它指示此StepExecution所属的JobExecution。对于给定的JobExecution和给定的Step名称,只能有一个StepExecution。 -
START_TIME: 表示执行开始时间的时间戳。 -
END_TIME: 表示执行完成时间的时间戳,无论成功或失败。此列中的空值(即使作业当前未运行)表示发生了某种类型的错误,框架在失败前无法执行最后一次保存。 -
STATUS: 表示执行状态的字符串。可能为COMPLETED、STARTED等。此列的对象表示是BatchStatus枚举。 -
COMMIT_COUNT: 在此执行期间步骤提交事务的次数。 -
READ_COUNT: 在此执行期间读取的项数。 -
FILTER_COUNT: 在此执行期间被过滤掉的项数。 -
WRITE_COUNT: 在此执行期间写入并提交的项数。 -
READ_SKIP_COUNT: 在此执行期间读取时跳过的项数。 -
WRITE_SKIP_COUNT: 在此执行期间写入时跳过的项数。 -
PROCESS_SKIP_COUNT: 在此执行期间处理时跳过的项数。 -
ROLLBACK_COUNT: 在此执行期间发生回滚的次数。注意,此计数包括每次发生回滚的情况,包括重试时的回滚和跳过恢复过程中的回滚。 -
EXIT_CODE: 表示执行退出代码的字符串。对于命令行作业,这可能会被转换为数字。 -
EXIT_MESSAGE: 表示作业如何退出的更详细描述的字符串。在失败的情况下,这可能包含尽可能多的堆栈跟踪信息。 -
LAST_UPDATED: 表示此执行最后一次被持久化的时间戳。
BATCH_JOB_EXECUTION_CONTEXT 表
BATCH_JOB_EXECUTION_CONTEXT 表存储了与 Job 的 ExecutionContext 相关的所有信息。每个 JobExecution 都对应一个 Job ExecutionContext,它包含了特定作业执行所需的所有作业级别数据。这些数据通常代表了在失败后必须恢复的状态,以便 JobInstance 能够“从上次中断的地方继续执行”。以下清单展示了 BATCH_JOB_EXECUTION_CONTEXT 表的定义:
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
以下列表描述了每一列:
-
JOB_EXECUTION_ID: 外键,表示此上下文所属的JobExecution。一个给定的执行可能关联多行记录。 -
SHORT_CONTEXT:SERIALIZED_CONTEXT的字符串版本。 -
SERIALIZED_CONTEXT: 整个上下文,已序列化。
BATCH_STEP_EXECUTION_CONTEXT 表
BATCH_STEP_EXECUTION_CONTEXT 表存储与 Step 的 ExecutionContext 相关的所有信息。每个 StepExecution 都对应一个 ExecutionContext,它包含了特定步骤执行所需持久化的所有数据。这些数据通常代表了失败后必须恢复的状态,以便 JobInstance 能够“从断点处继续执行”。以下清单展示了 BATCH_STEP_EXECUTION_CONTEXT 表的定义:
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;
以下列表描述了每一列:
-
STEP_EXECUTION_ID: 外键,表示此上下文所属的StepExecution。一个给定的执行可能关联多行数据。 -
SHORT_CONTEXT:SERIALIZED_CONTEXT的字符串版本。 -
SERIALIZED_CONTEXT: 序列化后的完整上下文。
归档
由于每次运行批处理作业时,多个表中都会产生记录,因此通常需要为元数据表制定归档策略。这些表本身旨在记录过去发生的事件,通常不会影响任何作业的运行,但涉及重启的几个重要例外情况除外:
-
框架使用元数据表来确定某个特定的
JobInstance是否曾经运行过。如果它已经运行过,并且该作业不可重启,则会抛出异常。 -
如果一个
JobInstance的条目在未成功完成的情况下被移除,框架会认为该作业是新的,而不是重启。 -
如果作业被重启,框架会使用任何已持久化到
ExecutionContext中的数据来恢复Job的状态。因此,从未成功完成的作业中删除此表中的任何条目,将导致它们在再次运行时无法从正确的点开始。
国际字符与多字节字符
如果在业务处理中使用多字节字符集(如中文或西里尔字母),这些字符可能需要持久化到 Spring Batch 的数据库结构中。许多用户发现,只需将数据库结构中的 VARCHAR 列长度加倍即可满足需求。另一些用户则倾向于在配置 JobRepository 时,将 max-varchar-length 设置为 VARCHAR 列长度的一半。也有用户反馈,他们在结构定义中使用 NVARCHAR 替代 VARCHAR。最佳方案取决于数据库平台及其在本地服务器上的配置方式。
元数据表索引建议
Spring Batch 在核心 jar 文件中为多个常见数据库平台提供了元数据表的 DDL 示例。这些 DDL 中不包含索引声明,因为用户可能希望采用的索引方式存在太多变数,这取决于其具体平台、本地惯例以及作业操作的业务需求。下表提供了 Spring Batch 提供的 DAO 实现将在 WHERE 子句中使用哪些列以及使用频率的参考信息,以便各个项目可以自行决定索引策略:
表 1. SQL 语句中的 WHERE 子句(不包括主键)及其大致使用频率。
| 默认表名 | WHERE 子句 | 频率 |
|---|---|---|
BATCH_JOB_INSTANCE | JOB_NAME = ? and JOB_KEY = ? | 每次启动作业时 |
BATCH_JOB_EXECUTION | JOB_INSTANCE_ID = ? | 每次重启作业时 |
BATCH_STEP_EXECUTION | VERSION = ? | 在提交间隔,即块处理时(以及在步骤开始和结束时) |
BATCH_STEP_EXECUTION | STEP_NAME = ? and JOB_EXECUTION_ID = ? | 每次步骤执行前 |