数据库
与大多数企业应用架构类似,数据库是批处理的核心存储机制。但由于批处理系统必须处理极其庞大的数据集,它与其他应用架构存在显著差异。例如,当一条SQL语句返回100万行数据时,传统的结果集通常会将所有返回结果保存在内存中直至全部读取完毕。针对这一问题,Spring Batch提供了两种解决方案:
基于游标的 ItemReader 实现
使用数据库游标通常是大多数批处理开发者的默认方法,因为这是数据库解决关系数据"流式"处理问题的方案。Java的ResultSet类本质上是一种面向对象的游标操作机制。ResultSet会维护一个指向当前数据行的游标。调用ResultSet的next方法会将游标移动到下一行。Spring Batch基于游标的ItemReader实现会在初始化时打开游标,并在每次调用read方法时将游标向前移动一行,返回一个可用于处理的映射对象。随后调用close方法以确保释放所有资源。Spring核心的JdbcTemplate通过回调模式解决了这个问题,它会完整映射ResultSet中的所有行并在将控制权返回给方法调用者之前关闭连接。然而在批处理中,这必须等待整个步骤完成。下图展示了基于游标的ItemReader工作原理的通用示意图。请注意,虽然示例使用SQL(因为SQL广为人知),但任何技术都可以实现这种基本方法。
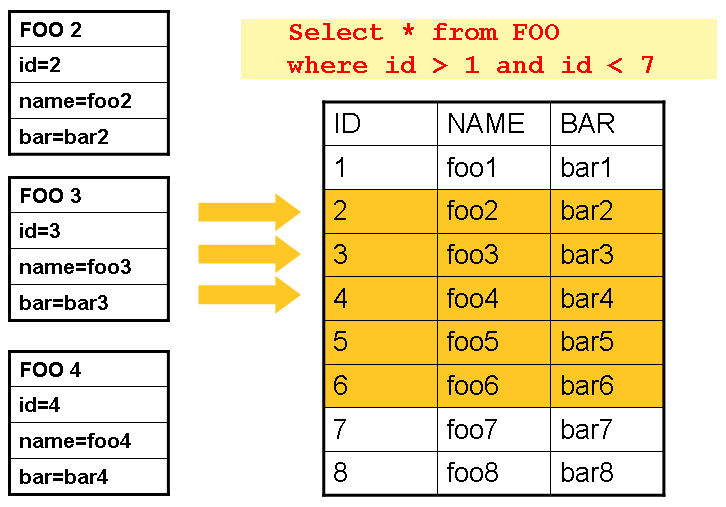
图 1. 光标示例
这个示例展示了基本模式。给定一个名为 'FOO' 的表,该表包含三列:ID、NAME 和 BAR,选择所有 ID 大于 1 且小于 7 的行。这将游标起始位置(第 1 行)定位在 ID 为 2 的行上。该行的结果应是一个完全映射的 Foo 对象。再次调用 read() 会将游标移动到下一行,即 ID 为 3 的 Foo 对象。每次 read() 后都会写出读取结果,从而允许这些对象被垃圾回收(假设没有实例变量保持对它们的引用)。
JdbcCursorItemReader
JdbcCursorItemReader 是基于游标技术的 JDBC 实现。它直接操作 ResultSet,并需要一个 SQL 语句来对从 DataSource 获取的连接执行操作。以下数据库模式作为示例:
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
);
许多人倾向于为每一行使用一个领域对象,因此以下示例通过实现 RowMapper 接口来映射 CustomerCredit 对象:
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}
由于 JdbcCursorItemReader 与 JdbcTemplate 共享关键接口,为了与 ItemReader 进行对比,查看如何使用 JdbcTemplate 读取数据的示例会很有帮助。在本示例中,假设 CUSTOMER 数据库中有 1,000 行数据。第一个示例使用 JdbcTemplate:
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());
运行上述代码片段后,customerCredits 列表包含 1000 个 CustomerCredit 对象。在查询方法中,从 DataSource 获取连接,对连接执行提供的 SQL 语句,并为 ResultSet 中的每一行调用 mapRow 方法。这与以下示例中展示的 JdbcCursorItemReader 方法形成对比:
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();
运行上述代码片段后,计数器等于 1,000。如果上面的代码将返回的 customerCredit 放入一个列表中,结果将与 JdbcTemplate 示例完全相同。然而,ItemReader 的最大优势在于它允许对数据进行“流式”处理。read 方法可以被调用一次,读取到的数据项可以通过 ItemWriter 写出,然后可以通过 read 获取下一个数据项。这使得数据的读取和写入可以以“块”的形式进行,并定期提交,这正是高性能批处理的核心所在。此外,它可以轻松配置并注入到 Spring Batch 的 Step 中。
- Java
- XML
以下示例展示了如何在 Java 中将一个 ItemReader 注入到 Step 中:
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}
以下示例展示了如何在 XML 中将一个 ItemReader 注入到 Step 中:
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>
附加属性
由于在Java中打开游标的方式多种多样,JdbcCursorItemReader 提供了许多可配置属性,如下表所示:
表 1. JdbcCursorItemReader 属性
| ignoreWarnings | 决定是否记录 SQLWarnings 或引发异常。默认值为 true(表示记录警告)。 |
|---|---|
| fetchSize | 向 JDBC 驱动程序提供一个提示,指定当 ItemReader 使用的 ResultSet 对象需要更多行时,应从数据库获取的行数。默认情况下不提供提示。 |
| maxRows | 设置底层 ResultSet 在任何时刻可容纳的最大行数限制。 |
| queryTimeout | 设置驱动程序等待 Statement 对象运行的秒数。如果超过限制,则抛出 DataAccessException。(详情请参阅驱动程序供应商文档)。 |
| verifyCursorPosition | 由于 ItemReader 持有的同一个 ResultSet 会传递给 RowMapper,用户可能自行调用 ResultSet.next(),这可能导致读取器内部计数出现问题。将此值设置为 true 时,如果 RowMapper 调用前后的游标位置不一致,将抛出异常。 |
| saveState | 指示读取器的状态是否应保存在 ItemStream#update(ExecutionContext) 提供的 ExecutionContext 中。默认值为 true。 |
| driverSupportsAbsolute | 指示 JDBC 驱动程序是否支持在 ResultSet 上设置绝对行。建议对支持 ResultSet.absolute() 的 JDBC 驱动程序将此值设为 true,因为它可能提高性能,尤其是在处理大型数据集时步骤失败的情况下。默认值为 false。 |
| setUseSharedExtendedConnection | 指示游标使用的连接是否应被所有其他处理使用,从而共享同一事务。如果设置为 false,则游标使用自己的连接打开,不参与为步骤其余处理启动的任何事务。如果将此标志设置为 true,则必须将 DataSource 包装在 ExtendedConnectionDataSourceProxy 中,以防止连接在每次提交后关闭和释放。将此选项设置为 true 时,用于打开游标的语句将同时使用 'READ_ONLY' 和 'HOLD_CURSORS_OVER_COMMIT' 选项创建。这允许在步骤处理期间启动的事务和提交过程中保持游标打开。要使用此功能,您需要支持此功能的数据库以及支持 JDBC 3.0 或更高版本的 JDBC 驱动程序。默认值为 false。 |
StoredProcedureItemReader
有时需要通过存储过程来获取游标数据。StoredProcedureItemReader 的工作方式类似于 JdbcCursorItemReader,不同之处在于它不是通过执行查询来获取游标,而是执行一个返回游标的存储过程。存储过程可以通过三种不同的方式返回游标:
-
作为返回的
ResultSet(由 SQL Server、Sybase、DB2、Derby 和 MySQL 使用)。 -
作为输出参数返回的引用游标(由 Oracle 和 PostgreSQL 使用)。
-
作为存储函数调用的返回值。
- Java
- XML
以下 Java 示例配置使用了与之前示例相同的 'customer credit' 示例:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
return reader;
}
以下 XML 示例配置使用了与之前示例相同的 'customer credit' 示例:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>
前面的示例依赖于存储过程来提供一个 ResultSet 作为返回结果(即前文中的选项 1)。
如果存储过程返回了一个 ref-cursor(选项 2),那么我们需要提供作为返回 ref-cursor 的输出参数的位置。
- Java
- XML
以下示例展示了在 Java 中如何处理第一个参数为引用游标的情况:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setRefCursorPosition(1);
return reader;
}
以下示例展示了在 XML 中如何处理第一个参数为引用游标的情况:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>
如果游标是从存储函数返回的(选项3),我们需要将属性 "function" 设置为 true。其默认值为 false。
- Java
- XML
以下示例展示了在 Java 中将属性设置为 true:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setFunction(true);
return reader;
}
以下示例展示了在 XML 中将属性设置为 true:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>
在上述所有情况下,我们都需要定义一个 RowMapper,以及一个 DataSource 和实际的过程名称。
如果存储过程或函数需要传入参数,则必须使用 parameters 属性进行声明和设置。以下以 Oracle 为例的示例声明了三个参数:第一个是返回游标的 out 参数,第二和第三个是接收 INTEGER 类型值的输入参数。
- Java
- XML
以下示例展示了如何在 Java 中处理参数:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
List<SqlParameter> parameters = new ArrayList<>();
parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR));
parameters.add(new SqlParameter("amount", Types.INTEGER);
parameters.add(new SqlParameter("custId", Types.INTEGER);
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("spring.cursor_func");
reader.setParameters(parameters);
reader.setRefCursorPosition(1);
reader.setRowMapper(rowMapper());
reader.setPreparedStatementSetter(parameterSetter());
return reader;
}
以下示例展示了如何在 XML 中处理参数:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean>
除了参数声明之外,我们还需要指定一个 PreparedStatementSetter 实现,用于设置调用的参数值。这与上述 JdbcCursorItemReader 的处理方式相同。附加属性 中列出的所有附加属性同样适用于 StoredProcedureItemReader。
分页 ItemReader 实现
使用数据库游标的替代方法是运行多个查询,每个查询获取结果的一部分。我们将这部分称为页面。每个查询必须指定起始行号以及我们希望在该页面中返回的行数。
JdbcPagingItemReader
分页 ItemReader 的一种实现是 JdbcPagingItemReader。JdbcPagingItemReader 需要一个 PagingQueryProvider,它负责提供用于检索构成页面的行的 SQL 查询。由于每个数据库都有自己提供分页支持的策略,我们需要为每种支持的数据库类型使用不同的 PagingQueryProvider。此外,还有 SqlPagingQueryProviderFactoryBean,它可以自动检测正在使用的数据库并确定适当的 PagingQueryProvider 实现。这简化了配置,是推荐的最佳实践。
SqlPagingQueryProviderFactoryBean 要求您指定 select 子句和 from 子句。您还可以提供一个可选的 where 子句。这些子句以及必需的 sortKey 将用于构建 SQL 语句。
在 sortKey 上设置唯一键约束非常重要,以确保在执行之间不会丢失任何数据。
当读取器被打开后,每次调用 read 方法会返回一个条目,其基本方式与其他 ItemReader 相同。当需要更多行数据时,分页操作会在后台自动进行。
- Java
- XML
以下 Java 示例配置使用了与之前展示的基于游标的 ItemReaders 类似的“客户信用”示例:
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}
以下 XML 示例配置使用了与之前展示的基于游标的 ItemReaders 类似的“客户信用”示例:
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean>
配置的 ItemReader 使用 RowMapper 返回 CustomerCredit 对象,RowMapper 必须被指定。pageSize 属性决定了每次查询运行时从数据库读取的实体数量。
'parameterValues' 属性可用于指定查询参数的 Map。如果在 where 子句中使用命名参数,则每个条目的键应与命名参数的名称匹配。如果使用传统的 '?' 占位符,则每个条目的键应为占位符的编号,从 1 开始。
JpaPagingItemReader
JpaPagingItemReader 是分页 ItemReader 的另一种实现。JPA 没有类似于 Hibernate StatelessSession 的概念,因此我们必须使用 JPA 规范提供的其他功能。由于 JPA 支持分页,所以在使用 JPA 进行批处理时,这是一个自然的选择。在读取每一页后,实体将变为分离状态,并且持久化上下文会被清除,以便在页面处理完成后允许实体被垃圾回收。
JpaPagingItemReader 允许您声明一个 JPQL 语句并传入一个 EntityManagerFactory。随后,它会在每次调用 read 方法时返回一个条目,其基本工作方式与其他 ItemReader 相同。当需要更多实体时,分页操作会在后台自动进行。
- Java
- XML
以下 Java 示例配置使用了与之前展示的 JDBC reader 相同的 'customer credit' 示例:
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}
以下 XML 示例配置使用了与之前展示的 JDBC reader 相同的 'customer credit' 示例:
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean>
配置好的 ItemReader 会以与上述 JdbcPagingItemReader 完全相同的方式返回 CustomerCredit 对象,前提是 CustomerCredit 对象具有正确的 JPA 注解或 ORM 映射文件。pageSize 属性决定了每次查询执行时从数据库读取的实体数量。
数据库 ItemWriters
虽然平面文件和XML文件都有特定的ItemWriter实例,但在数据库领域却没有完全对应的实现。这是因为事务已提供了所有必需的功能。对于文件而言,ItemWriter的实现是必要的,因为它们必须模拟事务行为——跟踪已写入的条目并在适当时机进行刷新或清理。数据库则不需要此功能,因为写入操作已包含在事务中。用户可以创建实现ItemWriter接口的自定义DAO,或使用为通用处理场景编写的自定义ItemWriter。无论采用哪种方式,它们都应该能正常工作。需要注意的一点是:通过批处理输出所提供的性能和错误处理能力。这在将Hibernate用作ItemWriter时最为常见,但使用JDBC批处理模式时也可能出现相同问题。假设我们谨慎处理刷新操作且数据无误,批处理数据库输出本身并无缺陷。然而,写入过程中的任何错误都可能导致混乱,因为无法确定是哪个具体条目引发了异常,甚至无法判断是否由单个条目导致,如下图所示:
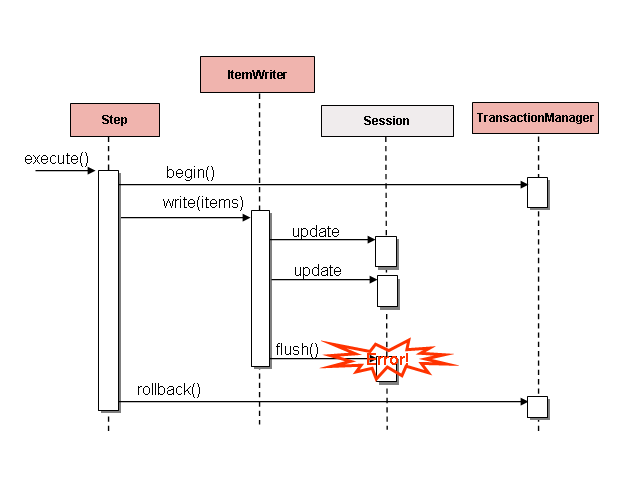
图 2. 刷新错误
如果在写入之前对条目进行了缓冲,那么任何错误都会在提交前的缓冲区刷新时才被抛出。例如,假设每个数据块写入20个条目,而第15个条目抛出了 DataIntegrityViolationException。就 Step 而言,所有20个条目都已成功写入,因为在它们实际写入之前无法得知是否发生了错误。一旦调用 Session#flush(),缓冲区被清空,异常随即出现。此时,Step 无法采取任何措施。事务必须回滚。通常,此异常可能导致该条目被跳过(取决于跳过/重试策略),之后便不再写入。然而,在批处理场景中,无法确定是哪个条目导致了问题。失败发生时,整个缓冲区正在被写入。解决此问题的唯一方法是每个条目写入后都进行刷新,如下图所示:
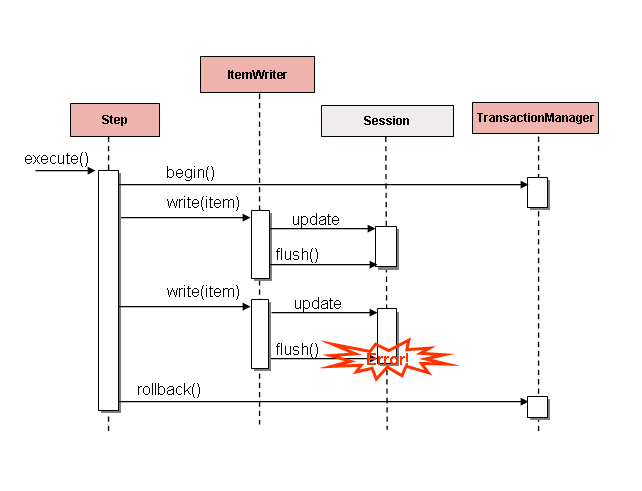
图 3. 写入错误
这是一个常见的使用场景,尤其是在使用 Hibernate 时。对于 ItemWriter 实现的一个简单指导原则是:在每次调用 write() 方法时都执行刷新操作。这样做可以确保项目能够可靠地被跳过,Spring Batch 会在内部处理错误发生后对 ItemWriter 调用的粒度控制。