配置和运行作业
在领域部分中,我们讨论了整体架构设计,以下图作为指导:
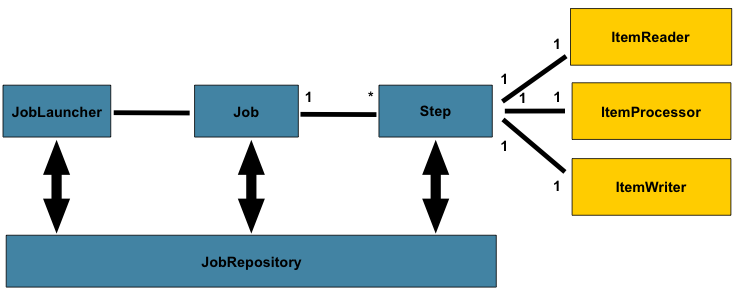
图 1. 批处理模式
虽然 Job 对象看起来像是步骤的简单容器,但您必须了解许多配置选项。此外,您还需要考虑关于 Job 如何运行以及其元数据在运行期间如何存储的诸多选项。本章将详细解释 Job 的各种配置选项和运行时注意事项。
章节总结
📄️ 批处理基础设施配置
如前所述,Spring Batch 依赖于多个基础设施 Bean 来运行作业和步骤,包括 JobOperator 和 JobRepository。虽然可以手动定义这些 Bean,但使用 @EnableBatchProcessing 注解或 DefaultBatchConfiguration 类来提供基础配置要简单得多。
📄️ 配置作业
Job 接口有多种实现方式。然而,这些实现方式被封装在提供的构建器(用于 Java 配置)或 XML 命名空间(用于基于 XML 的配置)之后。以下示例展示了 Java 和 XML 两种配置方式:
📄️ 配置 JobRepository
如前所述,JobRepository 用于对 Spring Batch 中各种持久化领域对象(如 JobExecution 和 StepExecution)进行基本的 CRUD 操作。许多主要框架功能(如 JobOperator、Job 和 Step)都需要它。
📄️ 配置 JobOperator
JobOperator 接口最基本的实现是 TaskExecutorJobOperator。它仅需要一个依赖项:JobRepository。其他所有依赖项,如 JobRegistry、MeterRegistry、TransactionManager 等,都是可选的。Spring Batch 提供了一个工厂 Bean 来简化此操作器的配置:JobOperatorFactoryBean。该工厂 Bean 会在 TaskExecutorJobOperator 周围创建一个事务代理,以确保其所有公共方法都在事务内执行。
📄️ 运行作业
启动批处理作业至少需要两样东西:要启动的作业和作业操作器。两者可以包含在同一个上下文中,也可以包含在不同的上下文中。例如,如果从命令行启动作业,则会为每个作业实例化一个新的 JVM。因此,每个作业都有自己的作业操作器。但是,如果在 HttpRequest 范围内的 Web 容器中运行,通常会有一个作业操作器(配置为异步作业启动),多个请求会调用该作业操作器来启动它们的作业。
📄️ 高级元数据使用
JobRegistry 用于追踪上下文中哪些作业可用,并可由 JobOperator 进行操作。当作业在其他地方(例如子上下文中)创建时,它还有助于在应用程序上下文中集中收集作业。您还可以使用自定义的 JobRegistry 实现来操作已注册作业的名称和其他属性。框架仅提供一种基于从作业名称到作业实例的简单映射的实现,即 MapJobRegistry。